Множество - кодовые сл
Cтраница 1
Множество кодовых слов образует группу ( по сложению по модулю 2), а множество кодовых слов с четным числом единиц образует подгруппу, этой группы. Если рассматриваемая подгруппа не исчерпывает всей группы, то множество кодовых слов с нечетным числом единиц является смежным классом по этой подгруппе и, следовательно, имеет то же число элементов, что и сама подгруппа. [1]
Показать, что множество кодовых слов для одного кода может быть получено путем некоторой фиксированной перестановки символов кодовых слов другого кода. [2]
Удобное графическое представление множества кодовых слов, удовлетворяющих свойству префикса, можно получить, представляя каждое кодовое слово концевым узлом на дереве. Дерево, представляющее кодовые слова кода III рис. 2.3.1, показано на рис. 3.2.2. Начиная с основания дерева, два ребра, ведущие к узлам первого порядка, соответствуют выбору между 0 и 1, рассматриваемым в качестве первой буквы кодовых слов. Подобно этому два ребра, исходящие из правого узла первого порядка, соответствуют выбору между 0 и 1 для второй буквы кодового слова, если первая буква была 1; такое же представление применимо и для других ребер. [3]
При любом заданном п множество кодовых слов, для которых хт, п О, образует подгруппу в группе кодовых слов. [4]
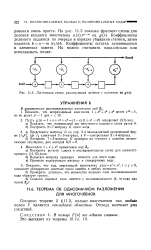 |
Логическая схема, реализующая деление с остатком на g ( x. [5] |
Проверить детально, что множество кодовых слов полиномиального кода образует группу. [6]
Поскольку при кодировании источников само множество кодовых слов заранее предопределено, то любой код можно характеризовать только числом кодовых слов М или скоростью кодирования JR - ogM и отображением последовательностей сообщений на выходе источника в множество кодовых слов. [7]
Аналогично, если A сг A - множество кодовых слов ( п, е) - кода с максимальной скоростью для ДК. [8]
Ниже будет описана предложенная Хаффменом процедура отыскания оптимального множества кодовых слов для кодирования ансамбля сообщений X, р ( х), удовлетворяющего теореме 14Л и обладающего тем свойством, что не существует другого множества кодовых слов, для которого средняя длина т меньше. [9]
Более того, левое неравенство справедливо для любого однозначно декодируемого множества кодовых слов. [10]
Раздел 5 посвящен метрической инвариантности кода и свойствам некоторых множеств кодовых слов фиксированного веса образовывать t - блоки. Показано, что любой код, параметры которого удовлетоворяют любому из неравенств d s или d s, метрически инвариантен. [11]
Линейный код С - это линейное подпространство в F: множество кодовых слов замкнуто относительно сложения векторов и покоординатного умножения на элементы из FV Размерность k ( иногда записываемая как dim С) равна размерности этого подпространства, код С содержит qk слов. [12]
Множество тг-мерных двоичных векторов с нулевым синдромом в точности совпадает с множеством кодовых слов. [13]
В этом параграфе будет дана предложенная Д. А. Хаффманом ( 1952) конструктивная процедура отыскания оптимального множества кодовых слов для кодирования данного множества сообщений. Под оптимальностью будет подразумеваться то, что никакое другое однозначно декодируемое множество кодовых слов не имеет меньшую среднюю длину кодового слова, чем заданное множество. Множество длин, задаваемое (3.3.8), обычно не минимизирует п, даже если на нем достигается граница в теореме 3.3.1. Вначале будут рассмотрены двоичные коды и затем будет дано обобщение на произвольный кодовый алфавит. [14]
Множество кодовых слов образует группу ( по сложению по модулю 2), а множество кодовых слов с четным числом единиц образует подгруппу, этой группы. Если рассматриваемая подгруппа не исчерпывает всей группы, то множество кодовых слов с нечетным числом единиц является смежным классом по этой подгруппе и, следовательно, имеет то же число элементов, что и сама подгруппа. [15]
Страницы: 1 2 3