Обучающее множество
Cтраница 2
Сеть обучается на этом обучающем множестве. Обучение состоит из предъявления входного вектора, вычисления выходного вектора, сравнивания выходного вектора с входным вектором, полученным в процессе наблюдений, и коррекции весов, минимизирующей разность между ними. Каждый входной вектор предъявляется по очереди, и сеть частично обучается. [16]
В то время, как обучающее множество используется для корректировки весов сети, контрольное множество служит для независимой проверки того, как нейронная сеть научилась обобщать информацию. [17]
В табл. 13.1 приведен пример обучающего множества. Здесь каждый объект имеет четыре атрибута: класс, рост, цвет волос и цвет глаз. [18]
Использование базы данных в качестве обучающего множества вызывает следующие трудности. Во-первых, информация в базе данных ограничена, так что не вся информация, необходимая для определения класса объекта, доступна. Во-вторых, доступная информация может быть повреждена или частично отсутствовать. Наконец, большой размер баз данных и их изменение со временем рождает дополнительные проблемы. [19]
О - множество, называемое обучающим множеством в IS; элементы О называются объектами, Q - множество атрибутов ( признаков), q e Q будет обозначать далее один атрибут из множества. [20]
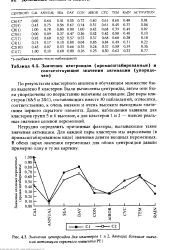 |
Значения центроидов ( промасштабированные и соответствующие значения активации ( упорядочен.| Значения центроидов для кластеров I и 2, дающих большие значения активации скрытого элемента РЕ1. [21] |
По результатам кластерного анализа в обучающем множестве было выделено 8 кластеров. Были вычислены центроиды, затем они были упорядочены по возрастанию величины активации. Две пары кластеров ( 6& 5 и 2& 1), составляющих вместе 30 наблюдений, относятся, соответственно, к очень низким и очень высоким выходным значениям первого скрытого элемента. Далее, наблюдения выявили для кластеров групп 5 и 6 высокие, а для кластеров 1 и 2 - низкие реальные значения целевой переменной. [22]
Совокупность пар x % dsj составляет обучающее множество. [23]
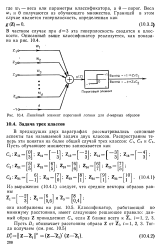 |
Линейный элемент пороговой логики для d - мерных образов. [24] |
Веса Wi и 0 получаются из обучающего множества. [25]
Вычислительная сложность алгоритма ID5R на больших обучающих множествах ниже, чем у метода грубой силы, что подтверждено эмпирическим сравнением на одних и тех же обучающих выборках. Результаты сравнения даны в работе Утгоффа. [26]
Если X - 0 ( то есть обучающее множество исчерпано), то КОНЕЦ. [27]
Выбирают несколько АСУТП, составляющих так называемое обучающее множество. [28]
Отличительной особенностью алгоритма RS1 является возможность обработки обучающего множества, в котором есть объекты с отсутствующими значениями атрибутов. Помещая неполностью заданные объекты во все возможные элементарные множества, алгоритм устраняет неполноту информации. [29]
Система наблюдается и собираются данные для составления обучающего множества. [30]
Страницы: 1 2 3 4 5