Моделирование - данные
Cтраница 1
 |
Принципиальная схема работы ERwin Examiner / ИМОШКЭИ 295. [1] |
Моделирование данных представляет собой сложную и ответственную задачу, поскольку от качества модели данных зависит в конечном счете эффективность и производительность ИС. Создание моделей для крупных ИС вручную уже немыслимо - для этого используют CASE-средства, такие, как ERwin и ему подобные. Однако хотя применение CASE-средств и облегчает техническую работу по созданию моделей, оно не гарантирует от ошибок и неточностей, которые допускаются при моделировании данных достаточно часто, особенно при создании больших моделей. Поиск и исправление таких ошибок без применения специализированных средств по трудуемкости может превосходить создание самой модели, поскольку придется анализировать модель, содержащую тысячи таблиц и десятки тысяч колонок и связей. [2]
При моделировании данных возникает проблема разноаспект-ного и многоуровневого представления данных и информации. Так, например, с одной стороны, необходимо учитывать взгляды пользователей, а с другой - аспекты компьютерной организации и ведения данных. В первом случае основной акцент делается на информационных потребностях пользователей, в понимании которых весьма важную роль играет интуиция. Во втором - основные проблемы связаны с конструированием системы, удовлетворяющей этим потребностям, при этом особую важность приобретают формальные, хотя и приближенные методы, позволяющие исходя из информационных потребностей синтезировать компьютер-ориентированные программы и структуры данных. [3]
Программа МОДА ( моделирование данных и алгоритмов) предназначена для организации исполнения модулей в заданной последовательности в режиме интерпретации операторов входного бланкового языка. Программа может осуществлять моделирование разнообразных алгоритмов, семантика которых полностью определяется составом используемой библиотеки модулей. [4]
Один из постулатов моделирования данных сводится к тому, что любые знания о реальном мире должны быть представлены допустимыми структурами. Насколько серьезно это ограничение. [5]
Указанные выше уровни моделирования данных мы будем именовать соответственно инфологической и диалогической областями. Есть и другие варианты терминологии многоуровневого описания данных и схем баз данных. [6]
Одним из основных требований к моделированию данных является обеспечение естественного отображения объектов предметной области, их свойств и отношений используемыми при моделировании типами структур, ограничений и операций с позиции пользователя системы. При этом следует добиваться естественности самих средств выражения информационных потребностей пользователей и простоты освоения последними этих средств. Для моделей данных, которые предназначены для выражения информацицонных потребностей пользователей, это требование становится принципиальным, поскольку модель данных выступает не только в качестве средства для определения конструкций данных, но и средством коммуникации между пользователем и системой. [7]
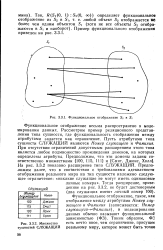 |
Функциональное отображение S2 в Si.| Множество сущностей СЛУЖАЩИЙ. [8] |
Функциональное отображение весьма распространено в моделировании данных. Рассмотрим пример реляционного представления типа сущности, где функциональность отображения между атрибутами задается как ограничение. Пусть атрибутами типа сущности СЛУЖАЩИЙ являются Номер служащего и Фамилия. При отсутствии ограничений допустимым расширением этого типа является любое подмножество произведения доменов, на которых определены атрибуты. На рис. 3.3.2 показано расширение типа СЛУЖАЩИЙ. [9]
Таким образом, чем большими возможностями моделирования данных и связей между ними обладает СУБД, тем легче пользователю формулировать и понимать запрос. [10]
Ключевой возможностью ERwin Examiner является обучение моделированию данных. [11]
 |
Использование графических элементов для объединения объектов на диаграмме.| Панель выравнивания ( Alignment. [12] |
Для освоения интерфейса JpRwin и изучения основ моделирования данных полезно использовать обучающий модуль. [13]
В решении одной из наиболее важных проблем моделирования данных - проблемы конструирования типов - существенная роль отводится технике абстракции. Примечательно, что, помимо таких видов отношений абстракции, как знак-тип и атрибут - объект, авторы рассматривают отношение тип - подтип, не характерное для моделей данных, поддерживаемых промышленными СУБД, но зато являющееся обычным для систем представления знаний. Этот факт, как и ряд других, упоминаемых далее, свидетельствует о неординарности позиции авторов, в соответствии с которой они излагают основной материал книги, позиции, определяемой наметившейся в последние годы тенденцией систематического обмена идеями в области данных в системах баз данных, языках программирования и системах искусственного интеллекта. [14]
Основная тематика нашей книги связана со средствами моделирования данных. В настоящей главе мы охарактеризовали применение этих средств при проектировании схемы и связанные с этим серьезные проблемы, показали, что такое положение, по-видимому, сохранится еще в течение определенного времени. Мир нуждается в более эффективных СУБД и, быть может, в более развитых моделях данных, но, что действительно необходимо, так это более совершенные способы использования уже существующих средств. [15]
Страницы: 1 2 3 4