Иерархическая модель - данные
Cтраница 1
Иерархическая модель данных ( файл) организует данные в виде иерархической древовидной структуры, состоящей из соподчиненных узлов и ветвей. Иерархия неизменно начинается с корневого узла, соединенного с порожденными ( зависимыми) узлами, причем каждый узел более высокого уровня связан только с одним узлом более низкого уровня. [1]
Иерархическая модель данных ( НМД) основана на использовании графического способа: она представляет собой дерево, в вершинах которого располагаются типы записей. Каждая из вершин связана только с одной вершиной вышележащего уровня иерархии. [2]
 |
Тип связи многие-ко-многим. [3] |
Иерархической модели данных присущи два важных внутренних ограничения. Первое из них состоит в том, что все типы связей должны быть функциональными1, второе - в том, что структура связей должна быть древовидной. Следствием этих ограничений является ряд особенностей структуризации данных. [4]
Иерархическим моделям данных присущи два внутренних ограничения. Первое ограничение - все типы связей должны быть функциональными, второе - структура связей должна быть древовидной. Следствием этих ограничений является необходимость соответствующей структуризации данных. В то же время иерархические модели довольно устойчиво применяются для составления различного рода классификаторов. [5]
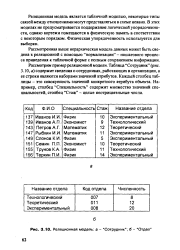 |
Реляционная модель. а - Сотрудник. б - Отдел. [6] |
Рассмотренная выше иерархическая модель данных может быть сведена к реляционной с помощью нормализации - пошагового процесса приведения к табличной форме с полным сохранением информации. [7]
В иерархической модели данных - сегмент, находящийся на предыдущем, более высоком уровне по отношению к связанному с ним порожденному сегменту. [8]
Сегмент иерархической модели данных, на который имеется ссылка ( указатель) от логически исходного сегмента другого дерева этой модели. [9]
Однако в иерархической модели данных действуют более жесткие внутренние ограничения на представление связей между сущностями, чем в сетевой модели. [10]
 |
Использование двух типов функциональной связи для представления типа связи многие-ко-многим. [11] |
Второе внутреннее ограничение иерархической модели данных - древовидная структура связей - не создает проблем, если данные имеют естественную иерархическую структуризацию. В противном случае, как это можно видеть на примере базы медицинских данных ( см. приложение), возникают определенные трудности, связанные с представлением ( М: N) - типов связей, а также с тем, что некоторые типы записей ( например, АНАЛИЗ) должны иметь более одного исходного типа записи. В этом случае необходимо определить покрывающие деревья [167], охватывающие все необходимые данные и в то же время удовлетворяющие ограничениям. На рис. 7.3.4 показаны покрывающие деревья для медицинской базы данных. [12]
Спецификационные операции в иерархической модели данных, основывающиеся на восходящей и нисходящей иерархической нормализации, селектируют множество записей в соответствии со структурой дерева. Сужение выборки может быть достигнуто спецификацией простейших условий, которым должны удовлетворять элементы данных. Так, например, селекция записи может осуществляться в соответствии с условиями, заданными для порожденной записи, исходной записи или в соответствии с их комбинацией. Далее на основе восходящей и / или нисходящей иерархической нормализации может быть осуществлена селекция других записей. [13]
Основными понятиями в иерархической модели данных являются тип записи и иерархическое отношение. Во многих моделях, в частности в модели данных СУБД ОКА, вместо понятия тип записи используется понятие тип сегмента. При этом каждый тип сегмента может иметь некоторое количество реализаций или экземпляров в базе данных. В этом смысле понятие тип сегмента аналогично понятию тип записи в модели данных DBTG. Иерархическое отношение соединяет два типа записей и представляет собой множество связей между экземплярами записей этих двух типов. [14]
Операции включения в иерархической модели данных IMS предполагают предварительную селекцию записи, которая будет родителем новой записи. Включение записи и подключение ее к родителю осуществляется одной операцией. Новая запись становится текущей в базе данных. [15]
Страницы: 1 2 3 4