Объем - алфавит
Cтраница 2
РПр чем совместное действие указанных выше причин, связанных с увеличением объема алфавита. [16]
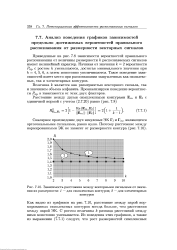 |
Зависимость расстояния между векторными сигналами от значения их размерности. 1 - для симплексных контуров. 2 - для элементарных. [17] |
Величина k является как размерностью векторного сигнала, так и значением объема алфавита. [18]
Нетрудно убедиться, что ни один групповой код с такими же объемом алфавита, длиной блока и числом проверочных символов не может иметь большего минимального расстояния, поскольку если выбрать все информационные символы, кроме одного, равными 0, то соответствующее кодовое слово будет иметь не более d ненулевых символов. [19]
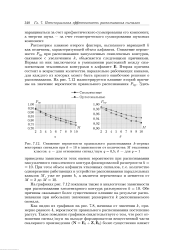 |
Снижение вероятности правильного распознавания - мерных. [20] |
Рассмотрим влияние второго фактора, вызванного вариацией k как величины, характеризующей объем алфавита. Снижение вероятности Рпр при распознавании зашумленных симплексных контуров, связанное с увеличением &, объясняется следующими причинами. Вторая причина состоит в возрастании количества параллельно работающих каналов, для каждого из которых может быть принято ошибочное решение о распознавании. [21]
 |
Снижение вероятности правильного распознавания / с-мерных. [22] |
Рассмотрим влияние второго фактора, вызванного вариацией k как величины, характеризующей объем алфавита. Снижение вероятности Рпр при распознавании зашумленных симплексных контуров, связанное с увеличением fc, объясняется следующими причинами. Вторая причина состоит в возрастании количества параллельно работающих каналов, для каждого из которых может быть принято ошибочное решение о распознавании. На рис. 7.12 иллюстрируется влияние второй причины на значение вероятности правильного распознавания Рпр. [23]
Рпр, чем совместное действие указанных выше причин, связанных с увеличением объема алфавита. [24]
Так как число кодовых слов в нелинейном коде не обязательно должно быть степенью объема алфавита, то удобно ввести новое обозначение. [25]
Дополнительный выигрыш в качестве можно достичь введением дополнительной избыточности при кодировании и увеличением размера объема алфавита как средства, при котором сохраняется фиксированная полоса частот. В частности, МНФ с решетчатым кодированием, с использованием относительно простых сверточных кодов, широко исследуется и много результатов имеется в технической литературе. Декодер Витерби для МНФ со сверточным кодированием сегодня используют для учета памяти, присущей и коду, и МНФ сигналу. ММС с сохранением полосы частот, был продемонстрирован с комбинированием сверточного кодирования и МНФ. [27]
Обычно же на практике коды строятся в обратном порядке: вначале выбирается количество информационных символов k, исходя из объема алфавита источника, а затем обеспечивается необходимая корректирующая способность кода за счет добавления избыточных символов. [28]
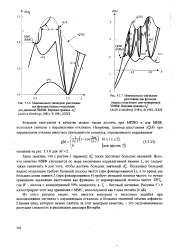 |
Минимальное евклидово расстояние как функция индекса модуляции для четверичной ЧМНФ. Верхняя граница dB2. [ Aulin viSundberg ( 1981, 1981IEEE ]. [29] |
Из этого рисунка видно, что имеется выигрыш в несколько децибел при использовании сигналов с парциальным откликом и больших значений объема алфавита. Главная цена, которую нужно платить за этот выигрыш качества, - это экспоненциально растущая сложность в реализации декодера Витерби. [30]
Страницы: 1 2 3 4