Подфайл
Cтраница 1
Подфайл 101112 будет передан на устройство 4, так как повторяется простой цикл. [1]
Подфайлы в условиях быстрой сортировки обрабатываются независимо друг от друга. На этой диаграмме показан результат разбиения каждого подфайла в процессе сортировки 200 элементов с отсечением файлов размером 15 и меньше. [2]
Протяженность подфайла определяется статьей справочника, а конкретнее, ключевым полем этого подфайла. Очевидно, записи подфайла содержат ключи, большие ключевого поля предшествующей статьи справочника и меньшие ( или равные), чем в данной статье. [3]
Если часть подфайла уже находится в области переполнения, то из области выделяется новая ячейка, в которую помещается вводимая запись. Эта ячейка включается в цепочку. В отсутствие - упорядоченности новая ячейка с записью помещается в конце цепочки и в нее заносится терминальный указатель. В случае сохранения упорядоченности указатели связного списка преобразуются и при необходимости выполняется переупорядочение подсписка. [4]
После обработки седьмого подфайла с каждого устройства на Т4 исчерпывается список и определяется конец файла. [5]
Добавить отсечение подфайлов малых размеров в восходящую сортировку слиянием связных списков из упражнения 8.36. Определить пределы, в рамках которых правильный выбор размеров отсекаемых файлов ускоряет действие полученной программы. [6]
При заключительном слиянии подфайлы считываются с каждого из входных устройств. В нашем примере на каждом входном устройстве находится по одному подфайлу. [7]
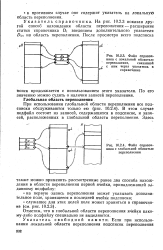 |
Файл справочника с глобальной областью переполнения. [8] |
В этом случае подфайл состоит из записей, содержащихся в подсписке, и записей, расположенных в глобальной области переполнения. [9]
Например, рассмотрим подфайл размером 5, содержащий ключи discreet, discredit, discrete, discrepancy и discretion. Все сравнения, выполненные с целью сортировки этих ключей, исследуют по меньшей мере семь символов, но в рассматриваемом случае можно было начать просмотр с седьмого символа, если бы была доступной дополнительная информация, фиксирующая тот факт, что первые шесть символов совпадают. [10]
Полученные при сортировке упорядоченные подфайлы размещаются в рабочих файлах, которые в дальнейшем используются для слияния. Если же все упорядоченные подфайлы поместить в один список, то выполнить их слияние будет очень трудно. [11]
Утилита сортировки распределяет упорядоченные подфайлы по разным спискам. Порядок распределения зависит от типа и вида сортировки. Для сбалансированного многопутевого слияния, краткое описание которого приводится ниже, файлы распределяются по устройствам равномерно. Так, на рис, 5.5.1 подфайл после формирования передается на отдельное устройство. Когда в каждом устройстве окажется ровно по одному подфай-лу, осуществляется возврат на первое устройство, и следующие подфайлы распределяются аналогичным образом. [12]
В конце концов рассортированные подфайлы, временно хранящиеся во внешней памяти, за несколько шагов сливаются в один файл. Если речь идет о небольшом количестве данных, то их можно все за один шаг рассортировать в основной памяти, однако при сортировке большого файла всегда приходится использовать такие внешние запоминающие устройства, как барабаны, магнитные ленты или диски. [13]
Сортировка меньшего из подфайлов, образовавшихся в результате разделения, первым, гарантирует, что размер стека в худшем, случае находится в логарифмической зависимости от размера исходного файла. На диаграмме отображены размеры для тех же файлов, что и представленные на рис. 7.5, при этом в трех первых случаях ( слева) применяется метод сортировки меньшего подфайла первым, в остальных трех случаях ( справа) к этому еще добавляется метод медианы трех. По этим диаграммам трудно судить о времени выполнения; этот показатель зависит от размера файлов в стеке, а не от их числа. Например, третий файл ( частично отсортирован) не требует большого стекового пространства, однако вызывает замедление сортировки, поскольку размеры обрабатываемых подфайлов большие. [14]
Найти среднее число подфайлов размера О, 1 и 2, когда быстрая сортировка используется для сортировки произвольно организованного файла из N элементов. [15]
Страницы: 1 2 3 4 5