Обучающая последовательность
Cтраница 3
После предъявления машине всех реализаций обучающей последовательности проводится поочередное распознавание указанных реализаций машиной. Если реализация одного из классов ошибочно относится к другому классу, то вес точки, соответствующей этой реализации, увеличивается на некоторую величину и соответственно будет увеличиваться потенциал, создаваемый этой точкой. После первого цикла распознавания процедура повторяется, и веса оставшихся нераспознанных реализаций вновь увеличиваются. Циклы повторяются до тех пор, пока последующий цикл перестанет давать увеличение степени распознавания по сравнению с предыдущим. [31]
Все объекты ( катализаторы) обучающей последовательности по целевому показателю ( активности, селективности) разбиваются на два класса. [32]
Взаимодействием системы со средой ( обучающей последовательностью) называется последовательность элементарных актов. Назовем состояние системы, предшествующее обучению, начальным, а возникающее после обучения - конечным. [33]
Затем строится обобщенный портрет для векторов обучающей последовательности, попавших в первую группу. [34]
В этом параграфе мы рассмотрим идею селекции обучающей последовательности: исключение из обучающей последовательности нескольких элементов с тем, чтобы с помощью оставшегося множества найти функцию, доставляющую меньшую гарантированную величину среднему риску. Заметим, что для задачи распознавания образов селекция обучающей последовательности не имеет смысла: решения, получаемые минимизацией эмпирического риска по всей обучающей выборке и по обучающей подвыборке, полученной исключением минимального числа элементов ( для того, чтобы подвыборка могла быть разделена безошибочно), достигаются на одном и том же множестве решающих правил. Это обстоятельство является следствием того, что функция потерь ( a - Fix, а)) 2 в задаче распознавания образов принимает только два значения: ноль и единица. [35]
Этот пример наглядно демонстрирует невыгодность использования случайных обучающих последовательностей. Вместе с тем он свидетельствует о серьезных отличиях описанного механизма обучения от механизма обучения, реализующегося в мозгу человека. [36]
Результаты экзамена в зависимости от числа просмотров обучающей последовательности приведены в таблице. Там же приведены результаты обучения методом псрцсптронной реализации. [37]
Подготовленный нами по данным работ [16-26] массив обучающей последовательности состоит из 100 объектов, которые распределяются в 66-мерном пространстве признаков. [38]
В этом параграфе мы рассмотрим идею селекции обучающей последовательности: исключение из обучающей последовательности нескольких элементов с тем, чтобы с помощью оставшегося множества найти функцию, доставляющую меньшую гарантированную величину среднему риску. [39]
Чисто теоретически для однозначного предсказания результатов величина обучающей последовательности ( число реализаций в массиве, используемом для обучения машины) должна превышать размерность пространства признаков, в котором проводится распознавание. Поскольку, однако, задача имеет статистический характер, то такого жесткого условия не ставится. В работе [9] методом математического эксперимента была проанализирована такая зависимость для случая гауссового распределения реализаций в пространствах признаков каждого из двух классов. Для NID 3 надежность распознавания существенно не зависит ни от размерности пространства признаков, ни от незначительного перекрывания границ классов в этом пространстве. Исходя из имеющегося опыта, свидетельствующего, что апостериорное число значащих признаков при распознавании катализаторов обычно не превышает 10 - 15, можно считать, что указанные цифры являются нижней границей величины массива обучающей последовательности в рассматриваемом круге задач. Желательно, однако, по возможности существенно увеличить этот массив. Дело в том, что указанные соотношения соблюдаются при достаточно точном определении самих значений признаков. В задачах распознавания катализаторов это имеет место не так часто, как указывалось выше. [40]
Эта функция строится по разным законам на обучающей последовательности конечной длины и используется на последовательности неограниченной длины. [41]
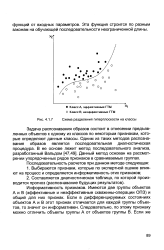 |
Схема разделения гиперплоскости на классы. [42] |
Эта функция строится по разным законам на обучающей последовательности неограниченной длины. [43]
Эта функция строится по разным законам на обучающей последовательности конечной длины и используется на последовательности неограниченной длины. [44]
После анализа литературных и расчетных данных проводится комплектация обучающей последовательности. Если исходная литературная экспериментальная информация достаточно большого и надежного объема, то дело ограничивается составлением по этой информации исходных таблиц для обучения машины, как это описано в предыдущей главе. Если исходная литературная информация отсутствует или ненадежна, то приходится ставить первоначальную серию экспериментов для создания обучающей последовательности. [45]
Страницы: 1 2 3 4