Информационная последовательность
Cтраница 2
Лпр, то искажения отсутствуют и информационная последовательность Ли передается получателю. Если результат сравнения не равен нулю, то в принятой последовательности появилась ошибка в проверочной или информационной части. [16]
 |
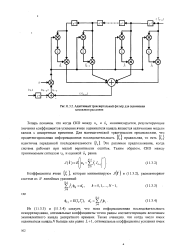
Функциональная схема кодирующего устройства для рекуррентного ( Vs-кода. [17] |
После того как первые два символа информационной последовательности будут занесены в регистр, сумматор по mod 2 определит первый проверочный символ апр2 в соответствии с рекуррентной формулой. [18]
Для исправления ошибки необходимо искаженные символы информационной последовательности Ли совместить с единицами корректирующей последовательности Лко. [19]
Чтобы расширить эти понятия на кодированную информационную последовательность, мы просто потребуем, чтобы сигнал, соответствующий кодовому биту или кодовому символу, замирал независимо от замираний сигналов, соответствующих другому кодовому биту или кодовому символу. Это требование может привести к неэффективному использованию имеющегося в распоряжение частотно-временного пространства и существование больших неиспользуемых участков в этом Двухмерном сигнальном пространстве. Чтобы этого не произошло, применяют перемежение: определенное число кодовых слов можно разнести во времени, частоте или одновременно по времени и частоте, таким образом, что сигналы, соответствующие битам или символам каждого кодового слова замирают независимо. Таким образом, мы предполагаем, что частотно-временное сигнальное пространство разделяется на неперекрывающиеся частотно-временные ячейки. Сигнал, соответствующий кодовому биту или кодовому, символу, передается внутри такой ячейки. [20]
Имеется 2К возможных выборов символов в информационных последовательностях К пользователей. Оптимальный детектор вычисляет корреляционные метрики для каждой возможной последовательности и выбирает последовательность, которая имеет наибольшую корреляционную метрику. Видно, что оптимальный детектор имеет сложность, которая растет экспоненциально с числом пользователей К. [21]
Предположим, что и и и - информационные последовательности, впервые отличающиеся в ( я 1) - м подблоке, и пусть s и s - соответствующие им выходные последовательности двоичного сверточного кодера. Рассуждая так же, как и при доказательстве леммы 6.9.1, находим, что (, где i изменяется от п 1 до п L, а / независимо изменяется от 1 до v, представляют собой множество vL независимых одинаково распределенных двоичных случайных величин. Так же как и в § 6.9, показывается, что после сложения последовательностей s и s со случайной последовательностью v отрезки получившихся последовательностей х и х от ( л 1)) - го до ( п L) - ro подблока статистически независимы и состоят из статистически независимых символов. [22]
 |
Адаптивный трансверсальный фильтр для оценивания канального рассеяния. [23] |
Из (11.3.3) и (11.3.4) следует, что пока информационная последовательность некоррелирована, оптимальные коэффициенты точно равны соответствующим величинам эквивалентного канала дискретного времени. [24]
Наличие подобного синхронного приема обеспечивает высокую поме-хозащиту передаваемых информационных последовательностей. [25]
Предположим, что используется алгоритм Витерби для детектирования информационной последовательности. [26]
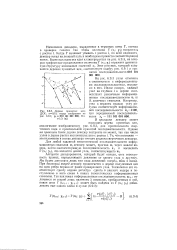 |
Дерево принятых цен. [27] |
На рис. 6.9.3 узлы отмечены в соответствии с информационными последовательностями, ведущими в них. Иначе говоря, каждый узел на глубине / в дереве соответствует различным информационным последовательностям игиз / А, двоичных символов. [28]
Положим далее, что на вход приемника поступают / г-разряд-ные информационные последовательности, отображающие передаваемые сообщения. [29]
 |
Диаграмма состояний и решетка состояний для сигнала ДБНП ( NRZI. [30] |
Страницы: 1 2 3 4 5