Поток - запросы
Cтраница 3
Для минимизации времени ответа на запрос необходим предварительный анализ потоков запросов. При обработке потоков запросов время ответа на отдельный запрос складывается из времени его исполнения, времени ожидания в очереди на обработку и времени пересылки из одной станции баз данных в другую. В этой связи при минимизации времени ответа на запрос необходимо учитывать рабочую нагрузку станций, участвующих в обработке запросов, и объемы пересылаемых данных, которыми обмениваются станции в процессе выполнения запроса. [31]
Способ формирования модели потока запросов сводится к следующему. Из описания потока запросов за базовый период времени определяется абсолютное число вхождений каждого ключевого значения, каждого ключевого имени в запросы всех степеней сложности. [32]

В этом случае поток запросов на повторение сообщений имеет характер простейшего и соответствует потоку сбоев в СПД и линии связи. [34]
В техническом задании ( ТЗ) указаны требования к какой-либо паре параметров, полностью определяющей функционирование АИПС. Например, заданы средняя интенсивность потока запросов и среднее время пребывания запросов в системе. [35]
Учитывая, что основной целью разработки и эксплуатации АИПС является удовлетворение информационных потребностей пользователей обслуживанием поступающих запросов, простейшей оценкой производительности системы могло, казалось бы, служить максимальное количество запросов, которое данный вариант АИПС в состоянии обслужить за единицу времени, например за год. Однако случайный характер поступления запросов ( потоки запросов могут быть даже не стационарными), неодинаковость времени обслуживания запросов различного типа, ограниченная надежность некоторых элементов системы и многие другие причины вносят в функционирование АИПС элементы нерегулярности, приводят к образованию очередей и перегрузок на отдельных операциях. [36]
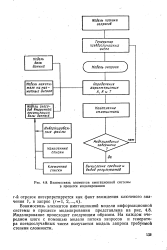 |
Взаимосвязь элементов имитационной системы в процессе моделирования. [37] |
Взаимосвязь элементов имитационной модели информационной системы в процессе моделирования представлена на рис. 4.8. Моделирование происходит следующим образом. На каждом очередном шаге с помощью модели потока запросов и генератора псевдослучайных чисел получается модель запроса требуемой степени сложности. [38]
Стек запросов к данным может сильно зависеть от того, как осуществляется планирование заданий в ЭВМ. В некоторых диалоговых системах практически невозможно воздействовать на поток запросов; однако в системах пакетной обработки соответствующее планирование заданий может стать ключом к эффективному использованию иерархической системы памяти. [39]
На рис. 33.9 показана также функция успеха для оптимального алгоритма замещения. Чтобы создать такой алгоритм, необходимо рассмотреть весь поток запросов, поступающих из программ. Заменяемая страница ( при оптимальном алгоритме замещения) должна быть той страницей, запрос на которую расположен дальше всех других в потоке запросов. [40]
 |
Иерархия языков формализованного описания вычислительных устройств. [41] |
До сих пор речь шла о так называемых детерминированных объектах ( устройствах, машинах, системах), при рассмотрении которых не учитываются действия случайных факторов. Учет случайных факторов ( сбоев, отказов, потоков запросов на обработку программ и др.), необходимость в котором возрастает по мере перехода к рассмотрению более сложных вычислительных устройств и комплексов, требует привлечения методов описания и анализа дискретных стохастических систем. Для анализа подобных систем широко используется статистическое моделирование на ЭВМ процесса функционирования. [42]
 |
К описанию регистра 78 13 20 31. [43] |
До сих пор речь шла о так называемых детерминированных объектах ( устройствах, машинах, системах), при рассмотрении которых не учитывается действие случайных факторов. Учет случайных факторов ( сбоев, отказов, потоков запросов на обработку программ и др.), необходимость в котором возрастает по мере перехода к рассмотрению более сложных вычислительных устройств и комплексов, требует привлечения методов описания и анализа дискретных стохастических систем. Для анализа подобных систем широко используется статистическое моделирование на ЭВМ процесса функционирования. [44]
Таким образом, существует реальная опасность, что память не будет действовать так, как ожидается. Ситуация усложняется в случае с мультипроцессором, когда каждый процессор посылает разделенной памяти поток запросов на чтение и запись, которые тоже могут быть переупорядочены. [45]
Страницы: 1 2 3 4