Обрабатываемая запись
Cтраница 3
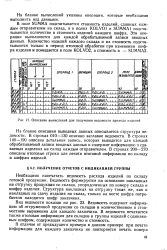 |
Описание вычислений для получения ведомости прихода изделий. [31] |
В поле SUMMA подсчитывается стоимость изделий, сданных каждым отправителем на склад, а в полях KOLVO1 и SUMMA1 подсчитываются количество и стоимость изделий каждого шифра. Эти операции выполняются для каждой обрабатываемой записи вводных данных. [32]
Например, если база данных реализована в виде комплекса дисковых файлов, как показано на фиг. Если к тому же для каждой обрабатываемой записи необходимо обеспечить дополнительно одно обращение к дисковому файлу, чтобы прочитать указатель адреса нужной записи на диске, максимальная скорость обработки информации снизится до 200 записей в минуту. Это соответствует потере 33 % пропускной способности системы. [33]
Базисный индексно-последовательный метод доступа может использоваться для занесения новых записей в файл данных, выборочной обработки или обновления записей, а также добавления новых записей в конец файла, что менее эффективно в общем случае по сравнению с использованием метода доступа с очередями. В макрокомандах READ и WRITE базисного индексно-последовательного доступа указывается ключ обрабатываемых записей, в остальном алгоритм совпадает с базисным последовательным методом доступа. Необходимо только при добавлении записей переменной длины к индексно-последовательному файлу данных предусмотреть рабочую область, превышающую объем памяти одной дорожки диска. Эта область описывается в Блоке управления данными и задается программистом в макрокоманде DCB. Для записей с фиксированной длиной такая область не обязательна, но может обеспечить выигрыш во время обработки записей. [34]
Информация, помещаемая в стек пульта, состоит из двух строк. Первая строка содержит символы из позиций 1 - 5 первой из обрабатываемых записей управляющего файла, в которой эти символы отличны от пробелов, а вторая - список имен макробиблиотек из первой записи управляющего файла. Режим STK действителен только тогда, когда определен режим CTL, и используется только в случае, если команда UPDATE вызывается из процедуры. Информация, помещенная командой UPDATE в стек пульта, может быть считана процедурой для последующего использования. [35]
Чтобы проиллюстрировать этот подход, предположим, что нам надо обработать 100 записей из индексно-последовательного файла. Пусть эти записи имеют длину, равную 500 символам, и пусть обрабатываемые записи распределены равномерно по файлу. Пусть на этом устройстве прямого доступа в цилиндре имеется 20 дорожек, а в каждой дорожке по пять записей. Предположим, далее, что всего в нашем наборе данных 1000 записей, и, таким образом, этот набор данных использует 10 цилиндров. Пусть в начале набора данных имеются дополнительно выделенные дорожки, содержащие индекс, так что общий объем выделенного этому набору данных участка составляет 11 цилиндров. Сначала метод доступа должен будет обратиться к дорожкам индекса, определить нужную позицию головок, установить головки в эту позицию, выбрать нужную головку и начать обработку записей, пока он не найдет нужную запись. Если да, то новая запись сравнивается с текущей. [36]
Коммуникационно-связанный модуль представляет собой конструкцию, обладающую процедурной связанностью и дополнительно тем, что все его функции связаны через используемые данные. Например, модуль читать следующую запись и обновить основной файл является коммуникационно-связанным по обрабатываемой записи. Недостатком подобных конструкций является сложность реализации функций, что может привести к ненадежности при модификациях. [37]
Выходная запись формируется программой пользователя в рабочей области, а по макрокоманде PUT в режиме пересылки пересылается в выходной буфер. Таким образом, использование макрокоманд GET и PUT в режиме пересылки приводит к двойной пересылке обрабатываемой записи: из входного буфера - в рабочую область и из рабочей области - в выходной буфер. [38]
Выше упоминалось, что байтовый переключатель может принимать более чем два состояния. Согласно алгоритму, позднее возникает необходимость по значению величины, содержащейся в переключателе, определить тип обрабатываемой записи и перейти к одной из трех подпрограмм. [39]
Здесь необходимо учитывать следующие характеристики: число цилиндров, в которых содержится набор данных, число обрабатываемых записей, распределение записей в наборе данных, а также геометрию устройства. [40]
Анализ методов оптимизации запросов на уровне доступа показывает, что наиболее эффективно реализуются те из них, которые минимизируют число обращений к внешней памяти ЭВМ. Очевидно, что минимального числа обменов с внешней памятью можно добиться при условии однократного считывания в ОЗУ каждой обрабатываемой записи. Поэтому в системах БД, работающих в оперативном режиме, возникает задача разработки таких механизмов поиска данных, которые оптимизируют время работы запросной системы за счет уменьшения числа повторных считываний записей. На этапе физической оптимизации число обращений к внешней памяти ЭВМ при реализации операций соединения является основным оптимизируемым параметром. Поскольку при произвольном обращении к записи требуется одно обращение к физическому блоку, то для выборки п записей в произвольном порядке необходимо п обращений к физическим блокам. [41]
Для всех памятей в RjTRANe ( кроме памятей, определенных описаниями COUNTER и MEMORY) формируется специальный дескриптор памяти, поименованный идентификатором - именем памяти. В первом слове ( счетчике) этого дескриптора размещается адрес собственно памяти: для регистра - это поле, содержащее текст регистра: для стека и вагона - пдрсс тонущего слова: для таблицы - адрес текущей строки; для файла - адрес текущей обрабатываемой записи. [42]
Последовательная обработка или обновление индексно-последовательного файла данных или его части производится с помощью так называемого режима сканирования. Для чтения очередной записи применяется макрокоманда GET в режиме пересылки или в режиме указания. Для задания начальной точки последовательности обрабатываемых записей используется макрокоманда SETL, Конечная точка этой последовательности отмечается макрокомандой ESETL. Таким образом, наличие нескольких участков последовательной обработки индексно-последовательного файла данных подразумевает несколько пар макрокоманд SETL - ESETL. Внутри этих участков обработка производится аналогично последовательному методу доступа с очередями. [43]
Термин сужение области поиска введен для представления группы методов со сходными характеристиками. Их очевидное преимущество состоит в том, что число обрабатываемых записей сокращается до размеров данной области. Недостатками же являются возможная необходимость продолжения поиска и более сложный, чем в связном списке, процесс добавления и удаления записей. [44]
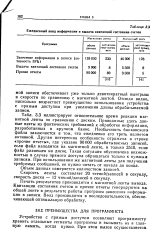 |
Ежедневный ввод информации и выдача квитанций состояния счетов. [45] |
Страницы: 1 2 3 4