Процедура - классификация
Cтраница 2
Эффективность решения задачи распознавания в конечном счете определяется тем, насколько эффективно организовано обучение распознающего устройства процедуре классификации. Поэтому основное внимание в проблеме распознавания образов уделяется задаче обучения распознаванию. [16]
 |
Алгоритм классификации взрывчатых веществ. [17] |
При классификации взрывчатых веществ следует учитывать ряд общих положений, которые могут быть рекомендованы при самой процедуре классификации и испытаниях перевозимых веществ. [18]
Анализ разрядов РМО, фиксирующих ошибки ПКЗ, РИ ОП и РА ОП, также производится в процедуре классификации ошибки. [19]
Как и все методы вывода, основанные на выборочных данных, процент правильных предсказаний и т-статистика имеют тенденцию к переоценке эффективности процедуры классификации. Это происходит потому, что обоснование решения производится по той же выборке, которая применялась для получения классифицирующих функций. Выражения, использованные при создании этих функций, чувствительны к выборочным погрешностям. [20]
Хотя обычно исследователи обращаются к классификации как к средству предсказания принадлежности к классу неизвестных объектов, мы можем использовать ее также для проверки точности процедур классификации. Для этого возьмем известные объекты ( которыми мы пользовались при выводе классифицирующих функций) и применим к ним правила классификации. Доля правильно классифицированных объектов говорит о точности процедуры и косвенно подтверждает степень разделения классов. [21]
Опыт применения математических методов классификации объектов в геологии показывает, что группирование на основе выделения наиболее аномальных и типичных объектов можно проводить с помощью иерархических агломеративных процедур классификации. [22]
 |
Диаграмма разброса векторов признаков ( - ясень, О - береза. [23] |
Таким образом, мы приходим к заключению, что поставленная задача включает в себя и элементы статистики, в связи с чем может потребоваться поиск такой процедуры классификации, которая сделает вероятность ошибки минимальной. [24]
Действительно, формальная теория подсказывает, что в принципе можно разработать очень много методов классификации, которые порождают, прежде всего, множество способов измерения, возможных процедур беспороговых классификаций, прямо связанных в конечном счете с топологическими процедурами ( взятие замыкания и дополнения, поиск предельных точек или точек накопления и пр. [25]
Однако главное внимание необходимо уделять тому, чтобы подмножество, используемое для вывода функций, было достаточно велико для обеспечения стабильности коэффициентов, иначе проверка будет обречена на неудачу с самого начала. Мы рассмотрели различные процедуры классификации, которые позволяют предсказать принадлежность конкретных объектов к определенным классам, дают нам полезную информацию: 1) об отдельных объектах; 2) о различиях между классами и 3) о способности переменных как целого точно различать классы. В нашем обсуждении до сих пор предполагалось, что выбор множества дискриминантных переменных является оптимальным. Теперь перейдем к выделению некоторых подмножеств этих переменных, которые оказываются более экономичными, но столь же эффективными, как все множество. [26]
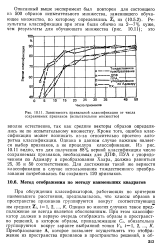 |
Зависимость правильной классификации от числа сохраняемых признаков ( испытательное множество. [27] |
Кроме того, ошибка классификации может возникать из-за относительно простого алгоритма классификации. Однако в данном случае важным является выбор признаков, а не процедура классификации. Из рис. 10.11 видно, что для получения 88 % верной классификации число сохраняемых признаков, необходимых для ДПФ, ПУА с упорядочением по Адамару и преобразования Хаара, должно равняться 25, 35 и 50 соответственно. [28]
При этом выделяемые подмножества Bh могут пересекаться. Таким образом, ТПС является классом ПС, а отнесение данной ПС к определенной ТПС является процедурой классификации ПС. [29]
Но любой документ полезен только тогда, когда он доступен и им пользуются. Отсюда и возникает необходимость в конфигурационном управлении, смысл которого заключается в возможно более раннем применении методов идентификации компонентов программного изделия, организации регулярного анализа проектных решений, введения процедур классификации изделий и контроля за их распространением. [30]
Страницы: 1 2 3