Разделение - файл
Cтраница 1
 |
Пример объединения файлов. [1] |
Разделение файлов выполняется по команде WRITE, которая позволяет вывести содержимое любого буфера или его части в заданный файл. [2]
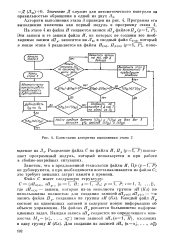 |
Блок-схема алгоритма выполнения этапа 3. [3] |
Разделение файла С на файлы И, Пр ( p l, P) выполняет программный модуль, который используется и при работе в сбойно-аварийных ситуациях. [4]
Процедура разделения файла на три части, которая рассматривалась в разделе 7.6, представляет собой элегантный способ извлечь пользу из отмеченного выше факта. На каждой стадии процесса разделения проверяется только один символ ( скажем, символ в позиции d), предполагая; что ключи, занимающие позиции от 0 до d - 1 и подлежащие сортировке, совпадают. Мы выполняем разделение на три части, помещая те ключи, d - й символ которых меньше d - ro символа разделяющего элемента, слева, те ключи, d - й символ которых равен d - му символу разделяющего элемента, в середине, а те ключи, d - й символ которых больше d - ro символа разделяющего элемента, справа. Далее мы выполняем обычные действия за исключением того, что мы сортируем средний подфайл, начиная с d 1-го символа. [5]
Эта программа производит разделение файла по старшим разрядам, после чего выполняет рекурсивную сортировку полученных подфайлов. Процесс разделение заканчивается, когда j становится равным i, т.е. когда все элементы справа от a [ i ] имеют 1 в d - й позиции, а все элементы слева от имеют 0 в d - й позиции. Дополнительная проверка, выполняемая непосредственно по окончании цикла, охватывает и этот случай. [6]
Показать, как производится разделение файла 1001110000010100, используя для этой цели программу 7.2 и несущественные модификации, предлагаемые по тексту. [7]
Функция поразрядной сортировки MSD выполняет разделение файла по первой цифре ключей, затем рекурсивно вызывает сама себя для обработки подфайлов, соответствующих каждому значению. На рис. 10.9 представлена структура этих рекурсивных вызовов для примера применения поразрядной сортировки MSD, показанного на рис. 10.8. Структура вызова соответствует многопутевому бинарному дереву, прямому обобщению древовидной структуры для двоичной быстрой сортировки, показанной на рис. 10.4. Каждый узел соответствует рекурсивному вызову сортировки MSD для некоторого подфайла. [8]
Как только вы запустили систему разделения файлов, все обращения к последним ( чтение / запись) проверяются операционной системой. [9]
Благодаря такому усовершенствованию понижается вероятность несбалансированного разделения файла. Однако, хотя и с очень малой вероятностью, все еще может иметь место случай очень большой несбалансированности при разделении. Если имеется опасение возникновения такого наихудшего случая, то его можно избежать переходом к методу сортировки с использованием корпоративной структуры после того, как число шагов разделения достигнет определенного уровня. [10]
 |
Элементы поля данных.| Подполя данных в поле. [11] |
Удобное в проектировании технологии обработки данных разделение файлов по назначению не учитывается управлением данными операционной системы, где существенным являются организация файлов и методы доступа. [12]
Кроме этих средств в организации процесса разделения файлов обычно участвуют и средства используемых пакетов СУБД. В частности, пакет dBASE IV обеспечивает четыре уровня защиты от одновременного доступа к файлам в среде ЛВС: захват файлов, захват записей, установку файла в исключительное владение одним пользователем и процедуру обновления ( транзакции) файла БД. [13]
Традиционный подход к обработке данных, вызывающий разделение файлов, почти во всех случаях требует копирования среды обработки информации, существовавшей до внедрения вычислительных машин. Поэтому разработке системы, описанной в предыдущей главе, обязательно предшествует изучение существующей технологии и документооборота и согласование каждой операции обработки данных с заказчиком. Преимущество метода отдельных файлов состоит в том, что он дает более быстрые результаты по сравнению с другим, интегрированным подходом, которому для достижения ощутимого успеха необходим расширенный системный анализ обработки данных совместно с изменением функций управления. Не исключение, когда недостаточно квалифицированные разработчики предпочитают штурмовать внедрение вычислительной машины, приспосабливая для решения сложной задачи известные функции накопления записей данных и хорошо сформулированные рутинные требования на обработку. В большинстве случаев уже такая автоматизация дает ощутимый эффект, поэтому однозначно отрицаться не может. [14]
Номер файла - это число от 1 до 255, которое используется для разделения файлов на группы. Системная программа спулинга % DSPOOL использует код назначения в качестве номера устройства, на которое должен быть направлен вывод. При написании собственных программ спулинга пользователь может использовать этот код любым требуемым способом. [15]
Страницы: 1 2 3