Вероятность - ошибка
Cтраница 3
Вероятность ошибки на букву представляет собой простой пример меры искажения при совпадающих алфавитах т и Z. В этом случае при одинаковом упорядочении алфавитов dti 1 -ог /), На рис. 1, а приведен соответствующий график для случая, когда алфавиты m и Z содержат по 3 буквы. Такая мера искажения может быть пригодна для оценки точности работы телетайпа или системы дистанционного набора. [31]
Вероятности ошибок 1-го и 2-го рода ( а и ( 3) однозначно определяются выбором критической области. Очевидно, желательно сделать как угодно малыми аир. Однако это противоречивые требования: при фиксированном объеме выборки можно сделать как угодно малой лишь одну из величин - а или р, что сопряжено с неизбежным увеличением другой. [32]
Вероятность ошибок уменьшается, если составитель в процессе выписки номеров страниц проверяет себя; если тщательно считывает перепечатанный оригинал указателя с карточками; если техн. [33]
Вероятность ошибки является ключевым параметром в распознавании образов. Это есть мера разделимости классов при данных распределениях, если предполагается использовать байесовский классификатор. Кроме того, вероятность ошибки характеризует качество классификатора по сравнению с байесовским классификатором для данных распределений. Вследствие важности этого параметра в главе 3 рассматривается задача его вычисления для данных распределений. Рассматривается также белее простая задача нахождения верхней границы вероятностл ошибки. [34]
Вероятность ошибки определяется условными плотностями вероятности р ( Х1а) и р ( Х / во) при наблюдении всего набора из п переменных. [35]
Вероятность ошибки является основным показателем качества распознавания образов, и поэтому ее оценивание представляет собой очень важную задачу. Как было показано в предыдущих главах, вероятность ошибки является сложной функцией, содержащей к-кратный интеграл от плотности вероятности при наличии сложной границы. [36]
Вероятность ошибки является ключевым параметром в распознавании образов. Это есть мера разделимости классов при данных распределениях, если предполагается использовать байесовский классификатор. Кроме того, вероятность ошибки характеризует качество классификатора по сравнению с байесовским классификатором для данных распределений. Вследствие важности этого параметра в главе 3 рассматривается задача его вычисления для данных распределений. Рассматривается также белее простая задача нахождения верхней границы вероятностл ошибки. [37]
Вероятность ошибки определяется условными плотностями вероятности р ( Х / а) и р ( Х / со2) при наблюдении всего набора из п переменных. [38]
Вероятность ошибки является основным показателем качества распознавания образов, и поэтому ее оценивание представляет собой очень важную задачу. Как было показано в предыдущих главах, вероятность ошибки является сложной функцией, содержащей к-кратный интеграл от плотности вероятности при наличии сложной границы. [39]
Вероятность ошибки при оптимальном приеме двоичных сигналов разных классов часто удобно выражать в некотором модифицированном универсальном виде. [40]
Вероятность ошибки 1-го рода оценивается как доля ошибок 1-го рода в данной подвыборке. [41]
Вероятность ошибки 2-го рода оценивается как доля ошибок 2-го рода в данной подвыборке. Вероятность ошибки 2-го рода с увеличением t убывает. [42]
Вероятность ошибки на бит для четырехфазной ДФМ с кодом Грея можно выразить через известные функции. [43]
Вероятность ошибки символа можно превратить в эквивалентную вероятность ошибки на бит. [44]
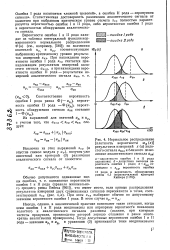 |
Нормальное распределение [ плотность вероятности wa ( x ] результатов измерений х ( а холостого сигнала аХол и близкого по величине аналитического сигнала аан. [45] |
Страницы: 1 2 3 4