Свойство - исходные данные
Cтраница 1
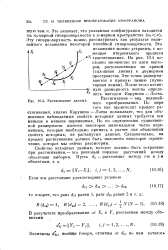 |
Растягивание данных. [1] |
Свойство исходных данных, которое должно быть сохранено при растягивании - это ранговый порядок расстояний между объектами выборки. [2]
Необходимо использовать широкие, гибкие модели, позволяющие учитывать свойства реальных исходных данных, в том числе их неопределенность. Переход от строгих классических моделей к более широким ( робастным и непараметрическим моделям) подробно излагается далее применительно к статистическим методам. [3]
Характеристики алгоритмов вычисляют при специально выбранных типовых моделях исходных данных, которые должны достаточно полно отражать свойства реальных исходных данных, для обработки которых предназначены алгоритмы. При этом выбираемые типовые модели должны быть по возможности простыми, а число моделей должно быть минимальным, иначе процедура аттестации стала бы слишком громоздкой. [4]
Как и в случае формирования нечетких данных, позиционный код получается применением к исходным данным дополнительного преобразования, искажающего свойства исходных данных. Кроме того, даже, если полагать форму единичного бита ( true) идеальным импульсом ( его длительность стремится к нулю), то, как известно, его спектральное разложение содержит более одной моды, т.е. данный вид кодирования информации избыточен по сравнению со спектральным представлением. Появившиеся спектральные составляющие, так или иначе, должны быть отражены в виде значимых битов, соответствующих модам, в исходном спектре, вообще говоря, отсутствующим и, возможно, характеризующим ( ошибочно) какой-то другой объект. [5]
Можем ли мы утверждать, что данные, полученные в результате информационного процесса, адекватны исходным. От каких свойств исходных данных и методов зависит адекватность результирующих данных. [6]
Методы получения различных оценок погрешностей можно разбить на четыре группы: аналитические, алгоритмические или программные, статистического моделирования и комбинированные. При аналитическом способе путем проведения аналитических оценок с применением определенных априорных сведений о свойствах исходных данных и решений задачи находятся априорные оценки погрешностей. Качество оценок здесь определяется искусством исследователя и количеством априорных сведений. В сложных случаях задачи получения требуемых оценок погрешностей целесообразно решать при помощи соответствующей библиотеки оценочных стандартных программ на ВМ. Разработка и применение таких программ составляют суть алгоритмического или программного метода. Для получения статистических оценок погрешностей полезно применять метод статистического моделирования [40, 276, 159] и для набора статистик применять числовой эксперимент. Наиболее эффективным оказывается комбинированный метод, когда весь алгоритм решения задачи расчленяется на части, для каждой из которых может быть с успехом применен один из четырех методов. [7]
 |
Основнче виды оценок погрешностей. [8] |
Методы получения различных оценок погрешностей можно разбить на четыре группы: аналитические, алгоритмические, или программные, статистического моделирования и комбинированные. При аналитическом способе путем проведения аналитических оценок с применением определенных априорных сведений о свойствах исходных данных и решений задачи находятся априорные оценки погрешностей. Качество оценок здесь зависит от искусства исследователя и качества априорных сведений. В сложных случаях задачи получения требуемых оценок погрешностей целесообразно решать с помощью соответствующей библиотеки оценочных стандартных программ на ЭВМ. Разработка и применение таких программ составляет суть алгоритмического, или программного, метода. Для получения статистических оценок погрешностей полезно применять метод статистического моделирования [84, 207] и для набора статистик применять числовой эксперимент. Наиболее эффективным оказывается комбинированный метод, когда весь алгоритм решения задачи и сама задача расчленяются на части, для каждой из которых может быть с успехом применен один из четырех методов. [9]
Всякий раз, когда мы имеем дело с большими множествами многомерных данных, задача их обработки упрощается, если удается обнаружить или навязать этим данным некоторую структуру. Поэтому можно предположить, что исходные данные подчиняются закону, который характеризуется определенным числом основных параметров. Минимальное число параметров и0, которые необходимо принять в расчет для объяснения наблюдаемых свойств исходных данных, называют истинной размерностью множества исходных данных или, что то же самое, истинной размерностью процесса, порождающего исходные данные. [10]
Всякий раз, когда мы имеем дело с большими множествами многомерных данных, задача их обработки упрощается, если удается обнаружить или павязать этим данным некоторую структуру. Поэтому можно предположить, что исходные данные подчиняются закону, который характеризуется определенным числом основных параметров. Минимальное число параметров п0, которые необходимо принять в расчет для объяснения наблюдаемых свойств исходных данных, называют истинной размерностью множества исходных данных или, что то же самое, истинной размерностью процесса, порождающего исходные данные. [11]
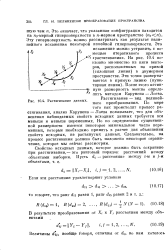 |
Растягивание данных. [12] |
На рис. 10.4 показано множество из пяти векторов, расположенных на кривой ( сплошная линия) в двумерном пространстве. После этого истинную размерность можно определить методом Карунена - Лоева. По мере того как происходит процесс растягивания, анализ Карунена - Лоева показывает, что для объяснения наблюдаемых свойств исходных данных требуется все меньше и меньше переменных. Но по определению существенной размерности имеется некоторое минимальное число переменных, которые необходимо принять в расчет для объяснения свойств исходных, не растянутых данных. Следовательно, на процесс растягивания должно быть наложено некоторое ограничение, которое мы сейчас рассмотрим. [13]
Страницы: 1