Сегмент - стек
Cтраница 2
Если указатель стека оказывается ниже нижней границы сегмента стека, как правило, происходит аппаратное прерывание, при котором операционная система понижает границу сегмента стека на одну страницу памяти. Программы не управляют явно размером сегмента стека. [16]
Оператор ASSUME указывает Ассемблеру, что для адресации каждой метки из сегмента CSEG надо пользоваться регистром CS. Другими словами, он идентифицирует CSEG как сегмент команд, а не сегмент данных, сегмент стека или дополнительный сегмент. [17]
Данная директива указывает параметры распределения памяти программы. Параметр Стек должен быть целым числом в диапазоне от 1024 до 65520, указывающим размер сегмента стека. Последние два параметра указывают соответственно минимальные и максимальные размеры динамически распределяемой области памяти. [18]
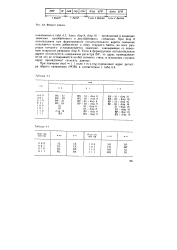 |
Формат команд. [19] |
Здесь disp 8, disp 16 - приводимые в командах значения однобайтового и двухбайтового смещения. Если в формируемом исполнительном адресе используется содержимое регистра ВР, то адрес принадлежит ( если это не оговаривается особо) сегменту стека, в остальных случаях адрес принадлежит сегменту данных. [20]
Как мы уже упоминали, в программе может быть до четырех видов сегментов: сегмент данных, сегмент команд, дополнительный сегмент и сегмент стека. [21]
Если указатель стека оказывается ниже нижней границы сегмента стека, как правило, происходит аппаратное прерывание, при котором операционная система понижает границу сегмента стека на одну страницу памяти. Программы не управляют явно размером сегмента стека. [22]
Следом за сегментом данных следует область стека. В ней располагаются локальные переменные и параметры-значения процедур и функций во время их работы по вызову. Сегмент стека содержится в регистре SS процессора. [23]
Если указатель стека оказывается ниже нижней границы сегмента стека, как правило, происходит аппаратное прерывание, при котором операционная система понижает границу сегмента стека на одну страницу памяти. Программы не управляют явно размером сегмента стека. [24]
Пусть в нашем распоряжении имеется схема сегментации того же типа, что и представленная на рис. 9.44. Адресное пространство определяется сегментом-описателем, который содержит информацию обо всех сегментах данного задания. Базовый регистр описателя ( DBR) должен быть установлен таким образом, чтобы указывать на сегмент-описатель. Поскольку обращения к сегменту связи и сегменту стека происходят часто, обычно выделяются специальные регистры, указывающие на эти сегменты. [25]
Остальные регистры предназначены для указания области ( сегмента) памяти, в которой находится адресуемая ячейка памяти. Приведем наименование регистров, связанное с основным их назначением: CS - сегмент программы, DS - сегмент данных, SS - сегмент стека, ES - дополнительный сегмент, IP - указатель команд. [26]
Определение наилучшего размера страниц требует уравновешивания нескольких параллельных факторов. Поэтому не существует абсолютного оптимального решения. Случайно выбранный текст, данные или сегмент стека не заполняют целое количество страниц. [27]
Определение наилучшего размера страниц требует уравновешивания нескольких параллельных факторов. Поэтому не существует абсолютного оптимального решения. Прежде всего, возникают два довода в пользу маленького размера страниц. Случайно выбранный текст, данные или сегмент стека не заполняют целое количество страниц. [28]
Когда выполняется системный вызов fork, вызывающий процесс обращается в ядро и ищет свободную ячейку в таблице процессов, в которую можно записать данные о дочернем процессе. Если свободная ячейка находится, системный вызов копирует туда информацию из ячейки родительского процесса. Затем он выделяет память для сегментов данных и для стека дочернего процесса, куда копируются соответствующие сегменты родительского процесса. Структура пользователя ( которая часто хранится вместе с сегментом стека) копируется вместе со стеком. Программный сегмент может либо копироваться, либо использоваться совместно, если он доступен только для чтения. Начиная с этого момента дочерний процесс может быть запущен. [29]
Теперь, зная, что хранится в данных таблицах, легко объяснить, как в системе UNIX создаются процессы. Когда выполняется системный вызов fork, вызывающий процесс обращается в ядро и ищет свободную ячейку в таблице процессов, в которую можно записать данные о дочернем процессе. Если свободная ячейка находится, системный вызов копирует туда информацию из ячейки родительского процесса. Затем он выделяет память для сегментов данных и для стека дочернего процесса, куда копируются соответствующие сегменты родительского процесса. Структура пользователя ( которая часто хранится вместе с сегментом стека) копируется вместе со стеком. Программный сегмент может либо копироваться, либо использоваться совместно, если он доступен только для чтения. Начиная с этого момента дочерний процесс может быть запущен. [30]
Страницы: 1 2