Словарь - пользователь
Cтраница 1
 |
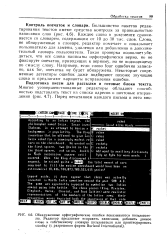
Диалоговое окно Орфография. [1] |
Словарь пользователя открывается в новом окне для редактирования. [2]
Разработка словаря пользователя необходима в связи с тем, что конечный пользователь не обязан владеть профессиональным языком предметной области, который использовался при построении БЗ. Интерфейс пользователя создается, как правило, путем доработки словаря общего кода. [3]
Интерфейс пользователя должен соответствовать словарю пользователя и уровню его подготовки. [4]
А некоторые настройки ( например, словари пользователей, записи средств Автозамена и Автотекст, а также макросы) требуют создания подпрограмм резервного копирования и восстановления, используемых для переноса указанных элементов с одного компьютера на другой. [5]
 |
Диалоговое окно Орфография. [6] |
В строке Нет в словаре отображается слово, не найденное в основном словаре или в открытых словарях пользователя. Строка Заменить на служит для выбора слова из списка Варианты для замены. Для новых слов можно выполнить их добавление в пользовательский словарь, который выбирается из списка Добавлять в, кнопка Добавить осуществляет добавление. [7]
Актуальность исследования этого аспекта определяется тем, что язык является основным средством общения в процессе извлечения знаний. В области лингвистических проблем наиболее важными являются понятия: общий код, понятийная структура, словарь пользователя. [8]
Найденное слово из основного словаря МультиЛекс может произнести почти человеческим голосом, если выбрать нужное английское слово и нажать кнопку Произношение. В третьей версии кнопка называется Звук и позволяет, кроме всего прочего, произносить целые фразы, введенные вами в словарь пользователя. [9]
В программах обработки текстов обычно имеется функция проверки синтаксиса, которая не только обнаруживает неправильно написанные слова, но и предлагает варианты их правильного написания. Один из подходов к проверке состоит в составлении отсортированного списка слов документа. Затем этот список сравнивается со словами, записанными в системном словаре и словаре пользователя; слова, отсутствующие в словарях, помечаются как возможно неверно написанные. Процесс выделения возможных правильных написаний неверно набранного слова может использовать приблизительное совпадение с образцом. [10]
Каждое слово в документе сравнивается со словарем, содержащим от 10 до 30 тыс. слов. Слова, не обнаруженные в словаре, редактор помечает и показывает пользователю для замены, удаления или добавления в дополнительный словарь пользователя. Такая проверка позволяет убедиться, что все слова написаны орфографически верно, но не фиксирует опечаток, приводящих к верному, но не подходящему по смыслу слову. Например, если слово four ошибочно записано, как for, опечатка не будет обнаружена. Некоторые современные детекторы ошибок даже подбирают похоже звучащие слова и предлагают варианты исправления ошибки. [12]
Ряд пакетов обработки текстов имеют средства контроля за правильностью написания слов. Каждое слово текстового документа сравнивается со словарем, содержащим от 10 до 30 тыс. слов. Слова, не обнаруженные в словаре, ТП помечает и показывает пользователю для замены, удаления или добавления в дополнительный словарь пользователя. Такая проверка позволяет убедиться, что все слова написаны с точки зрения орфографии верно, но не фиксирует опечаток, приводящих к верному, но не подходящему по смыслу слову. Например, если слово ТЕСТ ошибочно записано как ТЕКСТ, опечатка не будет обнаружена. Некоторые современные детекторы ошибок даже подбирают слова с похожим написанием и предлагают варианты исправления ошибки. [13]
Все дополнения и изменения вносятся в специальный подключаемый пользовательский словарь. Подключение нужного словаря для работы с конкретным документом выполняется выбором словарного файла в диалоговом окне Вспомогательные словари. Постепенно наполняясь конкретным содержанием, вспомогательные словари пользователя становятся мощным средством повышения производительности его труда. [14]
Очень важно понимать, что происходит, когда выполняется такая строка. Сначала интерпретатор рассматривает операторы как данные в процессе, называемом косвенным исполнением. Символ наклонной черты / указывает на то, что за ним следует литеральный объект ( данные), следовательно, имя выталкивается в стек операндов. Вложение операторов в фигурных скобках приводит к тому, что при первом чтении они рассматриваются подобно массиву данных; следовательно, они выталкиваются на стеке операнда. Затем оператор def выталкивает все эти объекты из стека операндов и создает элемент в словаре пользователя. [15]
Страницы: 1