Принятое слово
Cтраница 3
В дальнейшем при всех передачах, включая запись в память и считывание, слово передается вместе со своим контрольным разрядом. Если при передаче информации приемное устройство обнаруживает, что в принятом слове значение контрольного разряда не соответствует четности суммы 1 слова, то это воспринимается как признак ошибки. [31]
В дальнейшем при всех передачах ( включая запись в память и считывание) слово передается вместе со своим контрольным разрядом. Если при передаче информации приемное устройство обнаруживает, что в принятом слове значение контрольного разряда не соответствует четности суммы единиц слова, то это воспринимается как признак ошибки. [32]
С точки зрения групповой структуры удобно рассматривать строки ошибок. Система, только обнаруживающая ошибки, смотрит лишь, является ли принятое слово кодовым, и сигнализирует о наличии ошибки, если это не так. [33]
В некоторых случаях ошибки декодирования играют очень серы ную роль, в то время как отказ от декодирования является всего ли) досадной неприятностью. В таких случаях целесообразно исполь; вать очень неполный алгоритм декодирования, который декодир5 принятое слово только тогда, когда оно является кодовым. Эт алгоритм декодирует правильно тогда и только тогда - когда вект ошибки - нулевой, декодирует неправильно тогда и только тог; когда этот вектор совпадает с кодовым словом, и приводит к отка от декодирования в остальных случаях. GOBI дает с некоторым кодовым словом веса г, равна Рг ( 1 - P) n - l, i Р - вероятность искажения одного символа. [34]
В разделе 5.1 мы видели, что, даже-если локаторы ошибок декодеру известны, все же немедленное исправление ошибок вызывает определенные трудности. Оказывается, что проще подождать, пока искаженные символы будут выведены из буферного устройства, запоминающего принятое слово, а затем уже их исправлять. [35]
Совокупность выходных слов 1 ], которые ближе к кодовому слову ft) чем к какому-либо другому кодовому слову, обозначим Gfc. GM, и решение о том, какое сообщение было передано, будет производиться по принадлежности принятого слова ц той или иной области декодирования. [36]
Многочлены т - 1) ( х) и г 3) ( х) могут быть получены с помощью схемы, изображенной на рис. 5.6. Получаемые декодером из канала связи позиции подаются в 15-позицион-ный буферный регистр, изображенный на рис. 5.6 горизонтально вверху. После приема всех 15 позиций блока в буфере оказывается записанным многочлен R ( х), представляющий принятое слово. Начальное состояние обоих регистров является нулевым. [37]
Ошибки в данных k позициях будут сделаны с вероятностью p - kqk. При k 0 легко видеть, что вероятность ошибки в данных позициях уменьшается с ростом числа позиций. Это объясняет с вероятностной точки зрения, почему принятое слово лучше всего переводить в ближайшее к нему кодовое слово: вероятность того, что было передано более далекое слово, меньше. [38]
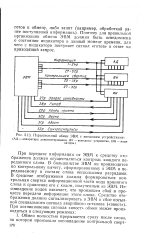 |
Параллельный обмен ЭВМ с внешними устройствами. ( АД - аппаратура документирования, ВУ - выводные устройства, ИН - индикаторы. [39] |
При передаче информации от ЭВМ к средству отображения должен осуществляться контроль каждого переданного слова. В большинстве ЭВМ он производится по контрольному вычету, сформированному в ЭВМ и передаваемому в составе слова несколькими разрядами. В средстве отображения должна формироваться контрольная свертка информационной части кода принятого слова и сравнение его с кодом, полученным из ЭВМ. Несовпадение кодов означает, что произошел сбой в процессе передачи информации этого слова. [40]
Передачу данных часто удобно рассматривать следующим образом. Система, исправляющая ошибки, переводит г в некоторое ( обычно ближайшее) кодовое слово. Система, только обнаруживающая ошибки, лишь проверяет, является ли принятое слово кодовым, и сигнализирует о наличии ошибки, если это не так. [41]
Остаток вписывается в контрольные разряды числа N вслед за его информационными разрядами. Принятое число N делится на q, и выделяется остаток r N. Элемент сравнения сравнивает rN и г, в случае их несовпадения выносит решение о наличии ошибки в принятом слове. Схема на рис. 3.102 6 иллюстрирует принцип контроля суммирующего устройства. Если остаток r N, полученный от деления числа / V на модуль q, не совпадает с rN, то элемент сравнения сигнализирует о наличии ошибок в работе устройства. [42]
Если произошло N - L a, а О, последовательных стираний, то первые N - L из них могут рассматриваться как проверочные символы и могут быть выбраны так, чтобы образовать кодовое слово при каждом выборе остальных стираний. Поэтому с принятой последовательностью согласуется 2а кодовых слов и декодирование неоднозначно. Представим себе, что во время работы изображенное на рисунке устройство производит N - L сдвигов. Принятое слово, у которого стирания заменены нулями, поступает в декодер в течение первых N единиц времени, когда ключ А замкнут. Ключ В замкнут в течение первых L единиц времени и регистр а наполняется символами принятой информационной последовательности. В течение последующих N - L единиц времени, когда принимаются проверочные символы, в регистре а не происходит сдвигов, затем производится считывание L информационных символов. Регистр b сдвигается в каждый момент из общего числа N L единиц времени. Нетрудно убедиться, что когда первый стертый символ выходит из регистра а, в регистре b будет содержаться стертая последовательность. [43]
Это вытекает из того, что а является корнем многочлена Du - f - D13 D2, поэтому Du D13 D2 имеет делителем 1 D - f D4 и, таким образом, является кодовым словом дуального кода. Da De, Du D7 - D и DU D3 1 являются кодовыми словами дуального кода. В регистр сдвига изображенного выше декодера вначале подается полное принятое слово; затем пороговое устройство производит исправление; после этого регистр сдвигается на одну позицию вправо, причем исправленный символ поступает слева. [44]
Однако существуют другие приложения, в которых нет возможности повторять недекодированные сообщения. В таких случаях отказ от декодирования столь же катастрофичен, как и ошибка декодирования. В приложениях подобного типа желательна максимальная вероятность правильного декодирования. Алгоритм полного декодирования не допускает отказа от декодирования принятого слова, даже если оно весьма сомнительно. Независимо от того, какая последовательность получена, принимается некоторое решение о переданном кодовом слове, даже если это решение - всего лишь тонкая догадка. [45]
Страницы: 1 2 3 4