Содержимое - сегмент
Cтраница 1
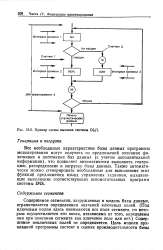 |
Пример схемы вызовов системы DL / 1. [1] |
Содержимое сегментов, загружаемых в модель базы данных, ограничивается определением значений ключевых полей. Под ключевым полем здесь понимаются все поля сегмента, по которым осуществляется его поиск, независимо от того, определены они при описании сегмента как ключевое поле или нет. Содержимое неключевых полей не определяется. [2]
Содержимое поименованного сегмента, записи или кортежа определяется один раз. Каждый программист, обращающийся к одному и тому же сегменту, должен рассчитывать на одинаковое содержимое этого сегмента. С помощью одной и той же совокупности сегментов могут быть определены различные азы данных. [3]
После определения содержимого сегментов и физических связей между ними необходимо решить следующую задачу проектирования - определить логические связи, которые обусловлены наличием ассоциаций типа М в композиционной модели. При этом определяются сегменты, участвующие в логических связях, и сегменты - кандидаты на вторичное индексирование. [4]
 |
Матрица использования элементов данных. [5] |
Для определения содержимого сегментов необходимо использовать коэффициенты производительности и режимы обработки, так как структура полей, составляющих сегмент, должна обеспечивать высокую производительность системы. [6]
Файл, представляющий содержимое сегмента оперативной памяти в момент начала выполнения задачи; для запуска задачи достаточно прочитать файл в оперативную память и передать управление в точку входа. [7]
 |
Матрица использования элементов данных. [8] |
Имея эту информацию, проектировщик может производить дополнительную оценку качества выбора содержимого предполагаемых сегментов. [9]
Предложение ОНО находится в начале подпрограммы, которая получает управление, если содержимое текущего Сегмента таблицы равно текущему значению ключа. [10]
Поэтому матрица использования элементов данных не должна быть решающим фактором при определении содержимого сегментов. [11]
 |
Матрица использования элементов данных. [12] |
Матрица использования элементов данных ( рис. 12.19) представляет собой одно из средств оценки содержимого сегментов. [13]
На рис. 19.2 приведен простой пример использования основных рассмотренных средств в модели прикладной программы, В примере выполняется операция обновления содержимого сегмента, при этом предполагается, что в большинстве случаев искомый сегмент хранится в базе данных. Для этого сначала выполняется операция GU, а затем - операция REPL. Если же в результате выполнения операции GU сегмент не найден, то он добавляется в базу данных. Процесс обновления повторяется в цикле 100 раз. Стрелками указаны места в модели для дополнительных макрокоманд, выполняющих регистрацию времени каждой операции ввода-вывода, времени всего процесса и значений счетчиков числа выполнений операций REPL и ISRT. При завершении 100 итераций обновления выборочные статистические данные выводятся на печать. [14]
Так как каждый член набора имеет только одного владельца, а последний может быть членом некоторого другого набора, процедуру определения содержимого сегментов и связей типа исходный - порожденный путем прохождения по ассоциациям типа 1 ( гл. Кроме того, в процедурах построения сетевой структуры можно использовать приемы и методы, рассмотренные в гл. Основное отличие состоит в том, что любой тип записи в системе КОДАСИЛ может быть членом любого числа наборов. Следовательно, вместо того чтобы из нескольких кандидатов выбрать только один тип физически исходного элемента, как это делается при определении исходных сегментов в структуре системы DL / 1, в построенную логическую модель системы КОДАСИЛ можно включить всех кандидатов на исходные элементы в качестве владельцев соответствующих наборов. Кроме того, все обнаруженные циклы необязательно представляют собой погрешности в структуре КОДАСИЛ, хотя информировать о них проектировщика по-прежнему необходимо. [15]
Страницы: 1 2