Поразрядная сортировка
Cтраница 3
 |
ТРЕХПУТЕВАЯ ПОРАЗРЯДНАЯ БЫСТРАЯ СОРТИРОВКА Мы делим файл на три части. слова, начинающиеся с букв от а до i, слова, начинающиеся с буквы j, и слова. [31] |
Сравнивая трехпутевую поразрядную быструю сортировку со стандартной поразрядной сортировкой MSD мы можем отметить, что она разбивает файл всего лишь на три части, так что она не использует всех преимуществ быстрого многопутевого разбиения, особенно на ранних стадиях сортировки. С другой стороны, на поздних стадиях поразрядной сортировки MSD появляется множество пустых корзин, но в то же время поразрядная быстрая сортировка хорошо приспособлена для случаев дублированных ключей, ключей, принимающих значения в узких диапазонах, файлов небольших размеров и многих других случаев, в условиях которых поразрядная сортировка MSD выполняется медленно. Особо важное значение приобретает то обстоятельство, что подобного рода разбиение хорошо подходит для случаев проявления различного рода закономерностей в разных частях ключа. Более того, для нее не нужны никакие вспомогательные файлы. В противовес всем этим достоинствам можно поставить тот факт, что требуются дополнительные операции обмена, чтобы реализовать многопутевое разбиение с помощью трехпутевого разбиения, когда число подфайлов велико. [32]
Чтобы должным образом выполнить сравнение рабочих характеристик поразрядной сортировки с характеристиками алгоритмов, построенных на основе операции сравнения, мы долее подробно должны проанализировать каждый байт ключей, а не ограничиваться только учетом числа ключей. [33]
Существуют два принципиально различных базовых подхода к поразрядной сортировке. Первый класс методов составляют алгоритмы, которые анализируют значение цифр в ключах в направлении слева направо, при этом первыми обрабатываются наиболее значащие цифры. Поразрядная сортировка MSD обобщает понятие быстрой сортировки, поскольку она выполняется за счет разделения сортируемого файла в соответствии со старшими цифрами ключей, после чего тот же метод применяется к подфайлам в режиме рекурсии. В самом деле, в условиях, когда в качестве основания системы счисления выбрана 2, мы реализуем поразрядную сортировку MSD тем же способом, что и быструю сортировку. Во втором классе методов поразрядной сортировки используется другой принцип: они анализируют цифры ключей в направлении справа налево, работая с сначала с наименее значащей цифрой. Поразрядная сортировка LSD в какой-то степени противоречит интуиции, поскольку основную часть процессорного времени затрачивается на обработку цифр, которые не могут повлиять на результат, однако эта проблема легко решается, и этот почтенный метод выбирается в качестве базового во многих приложениях сортировки. [34]
Этот результат обобщается путем его применения к поразрядной сортировке MSD. Тем не менее, поскольку основной интерес для нас представляет время выполнения сортировки, а не символы просматриваемых ключей, мы должны проявлять осторожность, поскольку время выполнения поразрядной сортировки пропорционально величине основания системы счисления Л и не имеет ничего общего с ключами. [35]
Некоторые из У л гори т ч он поразрядной сортировки которые предстоит рассмотреть и насюнщсй глин ь ис кольцуют свойство К-МЮ й принимать фнксиро ванную длину ( слова), л руг не ра. [36]
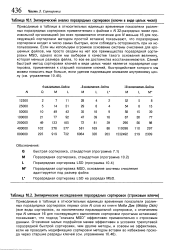 |
Эмпирический анализ поразрядных сортировок ( ключи в виде целых чисел.| Эмпирические исследования поразрядных сортировок ( строковые ключи. [37] |
Приводимые в таблице в относительных единицах временные показатели различных поразрядных сортировок применительно к файлам с N 32-разрядных чисел произвольной организацией ( во всех применяется отсечение для Л / меньше 16 для последующей сортировки методом простой вставки) показывают, что поразрядные сортировки входят в число самых быстрых, если соблюдать осторожность при их использовании. Если мы используем огромное основание системы счисления для крошечных файлов, мы просто сводим на нет все преимущества поразрядной сортировки MSD, однако если мы выберем в качестве такого основания величину, которая меньше размера файла, то все ее достоинства восстанавливаются. [38]
Приводимые в таблице в относительных единицах временные показатели различных поразрядных сортировок первых слов N слов из книги Моби Дик ( Mobby Dick) ( все виды сортировок, за исключением пирамидальной сортировки, с отсечением при Л / меньше 16 для последующего выполнения сортировки простыми вставками) показывают, что подход сначала MSD эффективен применительно к строковым данным. [39]
Чтобы добиться высокой производительности конкретного приложения, использующего поразрядную сортировку, следует ограничить число пустых корзин за счет выбора соответствующего значения как основания системы счисления, так и значения, в соответствии с которым отсекаются подфайлы небольших размеров. В качестве конкретного примера предположим, что требуется отсортировать 216 ( что-то около шестнадцати миллионов) 64-разрядных чисел. Чтобы поддерживать таблицу числа повторов, намного меньшую по размерам, чем размер файла, мы можем выбрать основание R - 216, для чего требуется проверка значений 16 разрядов, составляющих ключи. Но после первого разделения средний размер файла составит всего лишь 28, и выбранное основание системы счисления для таких небольших файлов становится слишком большим. Положение усугубляет еше и то обстоятельство, что таких файлов может быть очень много: порядка 216 в рассматриваемом случае. [40]
В главе 10 было показано, что при использовании поразрядной сортировки особое внимание должно быть уделено совпадающим ключам; то же самое справедливо и по отношению к поразрядному поиску. В этой главе предполагается, что все значения ключей в таблице символов являются различными. Это предположение не ведет к нарушению общности, поскольку для подержания приложений, содержащих записи с дублированными ключами, можно воспользоваться одним из методов, рассмотренных в разделе 12.1. При исследовании поразрядного поиска важно сосредоточиться на различных значениях ключей, поскольку значения ключей являются важными компонентами нескольких структур данных, которые рассматриваются в дальнейшем. [41]
Как уже говорилось в разделе 10.2, одна из наиболее привлекательных особенностей поразрядной сортировки обусловлена ее интуитивным и прямолинейным характером, позволяющим ее адаптироваться к сортирующим приложениям, в условиях которых ключами являются символьные строки. Это ее свойство особенно ярко проявляется в C и других средах программирования, в которых обеспечена прямая поддержка обработки строк. В условиях поразрядной сортировки мы просто используем основание системы счисления, соответствующее размеру байта. Чтобы извлечь цифру, мы загружаем байт, чтобы переместиться к следующей цифре, мы увеличиваем на единицу указатель строки. Сейчас мы рассматриваем строки фиксированной длины, а немного погодя мы убедимся в том, что с ключами в виде строк переменной длины легко работать, используя те же базовые механизмы. [42]
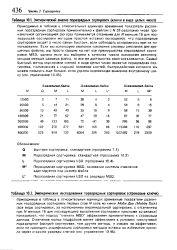 |
Эмпирический анализ поразрядных сортировок ( ключи в виде ц лын чисел. [43] |
N меньше 16 для последующей сортировки методом простой вставки) пдкэзычзют, что поразрядные сортировки вводят в число сам ы быстрых, если соблюдать осторожность при ид использовании. Если мы ислольдуем огрймнпе псноадние систем счнслеиия для крошечных файлов мы просто сводим на лет все преимущества поразрядной сортировки MSO. [44]
Трехпутевая поразрядная быстрая сортировка подходит к решению проблемы пустых корзин, характерной для поразрядной сортировки MSD, с применением трехпутевого разбиения, чтобы устранить значение одного байта и ( в рекурсивном режиме) работать с другими. Это действие соответствует замене каждого узла на пути вдоль средних связей по дереву, которое описывает рекурсивную структуру вызовов поразрядной сортировки MSD ( см. рис. 10.9) на троичное дерево, в котором каждой непустой корзине соответствует внутренний узел. Для полных узлов ( слева) такое изменение требует затрат времени и не влечет за собой заметной экономии пространства памяти, в то время как в случае пустых узлов ( справа), затраты времени минимальны, а экономия памяти значительная. [45]
Страницы: 1 2 3 4