Сравнение - среднее значение
Cтраница 3
Статистический метод, используемый для определения различий или сходства между двумя и более группами. Метод основывается на сравнении средних значений некоторых характеристик обеих групп. Упрощенные формулы дисперсионного анализа приведены ниже. [31]
Погрешность показаний поверяемой рабочей пурки должна определяться путем сравнения среднего значения натуры зерна, полученного при измерении рабочей пуркой, со средним значением натуры той же самой порции зерна, измеренной образцовой пуркой 2-го разряда. [32]
Наиболее часто на практике используются критерии сравнения средних значений и дисперсий для нормальных выборок, причем либо сравнивают параметр одной выборки с заданным значением, либо параметры двух выборок. Проверка однородности групп с нормальным распределением обычно выполняется путем сравнения средних значений и дисперсий выборок. Группы считаются однородными, если принимаются гипотезы равенства средних и дисперсий. [33]
Поправка к показаниям поверяемой образцовой пурки должна определяться путем сравнения среднего значения натуры зерна, полученного при измерении образцовой пуркой разрядом выше, оо средним значением натуры той же самой порции зерна, измеренным поверяемой образцовой пуркой. [34]
F в орбиталь неспаренного электрона очень мал. Единственный возможный способ установления типа образующейся парамагнитной частицы состоит в сравнении экспериментального среднего значения - тензора, равного 1 9988, с теоретическими предсказаниями. Другие значения значительно ближе к чисто спиновому - фактору. [35]
В решении задачи оценки эффективности применения средств, форм и методов обучения по определенным показателям особое место принадлежит задачам, связанным с необходимостью сравнивать между собой две группы наблюдений, полученных в разных условиях. В этом случае задача сравнения наблюдений по двум группам связана непосредственно как с задачей сравнения средних значений каждой выборки ( Xi и Х2), так и с задачей сравнения соответствующих дисперсий ( ai2 и 022) и этих выборок. [36]
Рассмотренные до сих пор вопросы касались определенных частных случаев. Так, при подсчете и применении средней квадратичной ошибки или доверительного интервала предполагалось, что мог быть лишь один-единственный источник ошибок, задаваемый методом анализа. Сравнение средних значений посредством i-критерия ограничивалось случаем только двух серий измерений. Решение этой проблемы на неоднородном числовом материале, при котором появляется более чем одна причина ошибок ( например, ошибка отбора пробы и ошибка анализа), а также сравнение более чем двух средних значений возможно при помощи простого дисперсионного анализа. Его применение предполагает нормальное распределение цифровых данных, отдельные значения которых получаются независимо одно от другого. [37]
Пурки 1-го разряда предназначены для поверки пурок 2-го разряда, пурки 2-го разряда - для поверки рабочих пурок. При поверке к показаниям образцовой пурки определяется поправка путем сравнения среднего значения натуры зерна, полученного при измерении образцовой пуркой разрядом выше, со средним значением натуры той же порции зерна, измеренным поверяемой образцовой пуркой. Допускаемые значения поправки к показанию образцовой пурки не должны превышать 1 5 г - для образцовой пурки 1-го разряда; 2 0 г - для образцовой пурки 2-го разряда. [38]
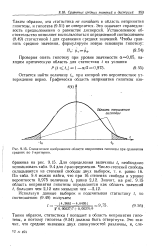 |
Схематичное изображение области непринятия гипотезы при сравнении средних по / - критерию. [39] |
Таким образом, эта статистика не попадает в область непринятия гипотезы, и гипотеза (9.51) не отвергается. Это означает справедливость предположения о равенстве дисперсий. Установленное обстоятельство позволяет воспользоваться определенной соотношением (9.49) статистикой t для сравнения средних значений. [40]
Этот вопрос оказывается не таким простым, как может показаться на первый взгляд. Поскольку измеряются значения случайных переменных, необходимо учитывать их стохастические особенности и быть готовым к различного рода осложнениям. При каждом отдельно взятом проигрывании модели на ЭВМ времена ожидания последовательно поступающих заявок на обслуживание будут сериально коррелированными ( иногда говорят, автокоррелированными); другими словами, вероятность того, что ( ге - ( - 1) - й заявке на обслуживание придется ждать, если п-я заявка также находится в состоянии ожидания, больше, нежели в том случае, когда п-я заявка принимается на обслуживание немедленно. Величины же ожидания сами по себе могут зависеть от дисциплины очереди. Модель может быть неустойчивой и иметь тенденцию к увеличению продолжительностей ожидания. Но даже и в том случае, когда система достигнет состояния устойчивости ( для чего может потребоваться большой промежуток времени имитирования), продолжительности ожидания могут и не иметь нормального распределения. Если пренебречь всеми этими соображениями и основываться просто на сравнении средних значений времени ожидания, полученных при прогонах имитационных моделей с дисциплиной очереди первого и второго типа, то можно прийти к ложным заключениям. [41]
Страницы: 1 2 3