Степень - параллелизм
Cтраница 2
Однако с ростом эффективности системы отношение D / E увеличивается. Эффективность, в свою очередь, отражает степень параллелизма, заложенную в систему. В частности, конструкции с крайними показателями характеризуются крайними значениями D. [16]
Затем продолжается процесс анализа. Аналитический план предписывает выполнение различных операций по сбору информации в определенной последовательности, а также степень параллелизма при их проведении. [17]
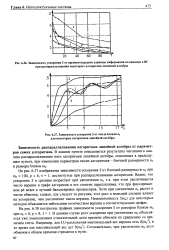
На рис. 6.37 изображены зависимости ускорения S от блочной размерности п при тъ 100, р 6, 1 1, достигнутые при распараллеливании алгоритмов. Видно, что ускорение S в среднем возрастает при увеличении пь, т.к. при этом увеличивается число вершин в графе алгоритма и его степень параллелизма, что при фиксированном р4 ведет к лучшей балансировке процессоров. Хотя при увеличении пь растет и число обменов, однако, как следует из рисунка, этот рост в меньшей степени влияет на ускорение, чем увеличение числа вершин. Немонотонность 8 ( пь) для некоторых методов объясняется небольшим количеством вершин в соответствующих графах. [19]
Указанные параметры являются обобщенными, поскольку они зависят от параметров основных элементов, входящих в систему, и архитектуры КТС. Так, производительность определяется, с одной стороны, быстродействием входящих в УВК элементов ( ЭВМ, преобразователей информации и др.), а с другой стороны, степенью параллелизма работы этих элементов в каждый момент времени. Среди существующих определений производительности наиболее целесообразным применительно к УВК АСУ ТП представляется определение ее через число эталонных задач [35], решаемых УВК в единицу времени. [20]
Степень параллелизма графа определяет максимально возможное число процессоров ВС для эффективного распараллеливания алгоритма при заданной агрегации операций алгоритма в вершины графа. При числе процессоров, большем степени параллелизма, в любой момент времени часть их обязательно будет простаивать. [21]
Вклад данной работы в решение этой проблемы имеет несколько аспектов. В частности, разработаны методы определения степени параллелизма программы и проверки ее однозначности. Однозначность программы означает независимость результатов вычислений от относительных скоростей согласованно выполняемых операторов. [22]
Каждый интерфейс базы данных получает результат выполнения запроса из БД не полностью, а по нескольку блоков ( страниц) данных, которые помещаются в основную память. Перед тем как механизм Пролога использует всю страницу данных, интерфейс базы данных будет активизирован повторно, в результате чего получается следующая страница ( страницы) данных. Такие средства предвыборки разработаны для уменьшения объема данных, загружаемых в память, а также для уменьшения времени ожидания механизма Пролога. Предвыборка может использоваться для повышения степени параллелизма, так как при этом могут быть активными одновременно несколько интерфейсов базы данных. [23]
Впервые мысль о применимости абстрактной интерпретации для анализа строгости была высказана в [69], который использовал эту методику также для исследования проблемы установления условной конечности времени вычисления выражения. Основной задачей здесь является повышение эффективности ленивой реализации функционального языка путем поиска возможности доступа к аргументам по значению, а не по необходимости без изменения условий окончания работы программы. Как мы видели в предыдущих главах, это устраняет необходимость в создании задержек для аргументов в SECD-машине и в то же время уменьшает количество структур данных, создаваемых во время прогона программы и обрабатываемых в дальнейшем сборщиком мусора. Более того, если при параллельной редукции графов известна строгость каждой определенной пользователем функций, то это позволяет производить вычисление строгих аргументов параллельно с вычислением функции, увеличивая тем самым степень параллелизма. [24]
Еще одним важным фактором является возможность совместного использования потоков на уровне пользователя и специализированного планировщика потоков. Рассмотрим, например, web - сервер на рис. 2.7. Пусть один рабочий поток только что заблокирован, а диспетчер и два оставшихся рабочих потока находятся в состоянии готовности. Система поддержки исполнения программ, которая обладает информацией о задаче каждого потока, выберет следующим диспетчера, чтобы он запустил следующий рабочий поток. Подобная стратегия увеличивает степень параллелизма в среде, где рабочие потоки часто блокируются на обращениях к диску. В целом специализированные планировщики потоков лучше управляют приложениями, чем ядро. [25]
Нужно сказать, что систематизация Флинна, а также позднее появившиеся классификации Хокни, Фенга, Хендлера и Скилликорна [9] не делают различий в организации распределенных вычислений с учетом взаимодействия процессов. Общим свойством, обеспечивающим возможность повышения производительности масштабируемых систем, как раз и является распределенность процессов вычислений и данных. Это свойство характерно и для SMP-архитектур, если принять во внимание типичную иерархию кэш процессора - основная память - подсистема ввода / вывода. Неудивительно, что не так давно появившиеся спецификации InfiniBand, RapidlO, развивающие идеи стандарта SCI ( Scalable Coherent Interface) и спецификаций Next Generation I / O, Future I / O, основаны на моделях распределенной обработки. Выигрыш от распределения вычислений и данных определяется степенью параллелизма, организацией взаимодействия и планированием процессов. [26]
Принципы фон - Неймана практически можно реализовать множеством различных способов. Архитектура не определяет особенности реализации аппаратной части ЭВМ, времени выполнения команд, степени параллелизма, ширины шин и других аналогичных характеристик. Архитектура отображает аспекты структуры ЭВМ, которые являются видимыми для пользователя: систему команд, режимы адресации, форматы данных, набор программно-доступных регистров. Одним словом, термин архитектура используется для описания возможностей, предоставляемых ЭВМ. Весьма часто употребляется термин конфигурация ЭВМ, под которым понимается компоновка вычислительного устройства с четким определением характера, количества, взаимосвязей и основных характеристик его функциональных элементов. Термин организация ЭВМ определяет, как реализованы возможности ЭВМ. [27]
Фортран, Паскаль и Кобол. Такие компьютеры имеют хранящуюся в их внутренней памяти программу-транслятор, с помощью которой прикладные программы переводятся с языка программирования высокого уровня на машинный язык, понятный данному компьютеру. Если ЭВМ полностью переводит прикладную программу перед ее выполнением на машинный язык и в этой форме помещает на хранение в память, то в таком случае программа-транслятор носит название компилятора. Если же каждая команда прикладной программы выполняется сразу после ее преобразования без промежуточного помещения в память, то тогда программу-транслятор называют интерпретатором. Поскольку компилятор вместе с преобразованной в машинный код прикладной программой или соответственно интерпретатор необходимо разместить в основной памяти ЭВМ, то это заставляет увеличивать ее емкость. Кроме того, время преобразования обходится тем дороже, чем меньше обрабатывающие мощности ЦП компьютера и чем меньше степень временного параллелизма используемых ИС, который вводится для по крайней мере частичной компенсации теряемой скорости обработки. В итоге возрастают и объем аппаратных средств компьютера, и их стоимость. В отношении больших ЭВМ уже давно доказано, что эти деньги себя оправдывают. Тот факт, что данный подход оказался приемлемым и для микроЭВМ, подтверждается существованием бытовых, конторских и персональных компьютеров. Эти компьютеры содержат гораздо больше ИС, чем простейшие микроЭВМ, программируемые только на машинном языке, которые мы рассмотрели выше. [28]
Другие приложения, которые различаются главным образом по времени, необходимом для их создания, включают в себя анализ высказываний и анализ сложности. Первый связан с определением того, какое из рекурсивных уравнений в описаниях функции потребуется при данном вызове этой функции. Это важно в компьютерах с параллельной архитектурой, в которых может быть необходим удаленный доступ к разделяемым кодам. Путем определения того, какие части этого кода необходимы ( высказывания), можно значительно сократить количество сообщений, которые эти высказывания пересылают. Анализ сложности также важен для параллельных машин, особенно для машин с улучшенными структурными элементами. Если выражение содержит подвыражение, которое может быть вычислено независимо, например аргументы применения функции или выражение, значением которого является функция и которое применяется к выражению аргумента, то независимые вычисления могут быть поручены ( разбросаны) различным процессорам для параллельного выполнения. Однако такое распределение приводит к дальнейшему росту обмена информацией, и если стоимость разделения вычислений преобладает над выигрышем по времени выполнения вычислений, то смысла увеличивать степень параллелизма таким образом нет. Задача, поэтому, заключается в том, чтобы заранее, на этапе компиляции, знать, как долго будет происходить вычисление подвыражений. Возможно, что на это будет указывать некая мера сложности, определенная для выражений, и если они были выражены в терминах некой нестандартной семантики и домена, то абстрактная интерпретация может стать формальной основой для подобного анализа. [29]
Страницы: 1 2