Адрес - документ
Cтраница 3
Из всех элементов описания для этой цели могут быть использованы лишь заглавия и подзаголовочные данные, а также отчасти заглавия серий в надзаголовочных данных. Эти данные не всегда в достаточной мере раскрывают содержание документа. Кроме того, заглавия, которые даются документам их авторами, составителями или издателями иногда не соответствуют содержанию документов, а необходимость в сохранении точного адреса документа не позволяет произвольно менять его заглавие. Тем не менее в реферативных журналах все чаще практикуется замена заглавий, несоответствующих содержанию статей, другими более точными названиями. Необходимо отметить, что такая практика применима лишь в отношении журнальных статей, заглавия которых не несут большой адресной нагрузки. [31]
В двухконтурной ИПС информационный поиск производится в два этапа: сначала выявляются адреса документов с требуемой информацией, а затем по этим адресам в ЗУпас отыскиваются и сами документы или их микрокопин. Если для выявления адресов искомых документов применить быстродействующую ЭЦВМ ( что и делается в некоторых больших ИПС), то этот этап информационного поиска выполняется очень быстро - иногда всего за несколько секунд. Когда выявлены адреса документов с требуемой информацией, то время обращения в ЗУпас на втором этапе информационного поиска также не может быть большим. Таким образом, весь процесс поиска требуемой информации в массиве, содержащем сотни тысяч и миллионы страниц документов, может производиться в таких ИПС за 20 - 30 сек. [32]
Списки адресов а в ИПС значительно больше по размерам, чем в СУБД. Поэтому для организации эффективного доступа к данным индекс может храниться, например, в трех разных файлах, связанных указателями. Первый файл - индексный, состоит из полей: слово; указатели пересылок. Второй файл - пересылок, состоит из полей: номер Документа; адрес документа. Третий файл содержит тексты документов. [33]
Списки адресов а в ИПС значительно больше по размерам, чем в СУБД. Поэтому для организации эффективного доступа кданным индекс может храниться, например, в трех разных файлах, связанных указателями. Первый файл - индексный, состоит из полей: слово; указатели пересылок. Второй файл - пересылок, состоит из полей: номер документа; адрес документа. Третий файл содержит тексты документов. [34]
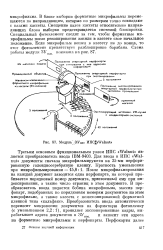 |
Модуль ЗУпас HnC ] [ Walnut. [35] |
Третьим основным функциональным узлом ИПС Walnut является преобразователь ввода IBM-9403. Для ввода в ИПС Walnut документы сначала микрофильмируются на 35-мм перфорированную галоидносеребряную пленку. После микрофильмирования на каждый документ заводится одна перфокарта, на которой пробивается порядковый номер документа, присвоенный ему при индексировании, а также число страниц в этом документе. В преобразователь ввода подается бобина микрофильма, массив перфокарт, подобранных по порядковым номерам документов на этом микрофильме, а также кассета с неэкспонированной форматной пленкой типа кальфакс. Преобразователь ввода автоматически переносит микрокопии документов на форматную фотопленку ( с уменьшением 2 2: 1), проявляет экспонированные кадры, вырабатывает адреса документов в ЗУпас и заносит эти адреса на форматные микрофильмы и перфокарты. [36]
 |
Схема взаимодействия с внешними программами Gopher - сервера. [37] |
В информационной системе Gopher имеется два вида стандартных серверов. Обычные или общие серверы обеспечивают доступ к ресурсам файловой системы: файлам и директориям. Кроме обычных серверов имеются еще поисковые серверы, которые выполняют запросы клиентов. Поисковый сервер используется для обслуживания запросов, составленных из ключевых слов. В ответ на такой запрос он возвращает список документов, удовлетворяющих запросу. Фактически происходит генерация нового документа Gopher на лету. При описании поисковых серверов часто используют понятие поиск по полному тексту документа, что в общем случае не соответствует реальному положению вещей. Обычно поиск осуществляется при помощи файлов индексов. Индексы составляются специальной программой для каждого файла один раз. Индексный способ поиска - процедура, достаточно известная и широко применяемая в информационно-поисковых системах. Обычно индекс состоит из слов и адресов документов, в которые это слово входит. [38]
Страницы: 1 2 3