Различный тип - данные
Cтраница 2
Часто возникает необходимость хранить связанную информацию для обработки различных типов данных. Такой порядок требует создания отдельного массива для каждого типа данных, а для установления соответствия между ними введены соответствующие индексы. [16]
Чтобы сгенерировать семейство родственных классов для работы с различными типами данных, необходимо определить единственный шаблон класса. [17]
Помимо рассмотренного сценария клиент-интерфейс-реализация существует много других способов поддержки различных типов данных. Эта концепция выходит за рамки определенного языка программирования, либо метода реализации. Одна из наиболее важных особенностей C заключается в понятии классов, которые предоставляют удобный метод описания и реализации типов данных. В этой главе за основу взято простое решение, но впоследствии практически повсеместно будут использоваться классы. Глава 4 посвящена применению классов для создания базовых типов данных, что важно для разработки алгоритмов. [18]
База данных постоянно содержит некоторую совокупность сведений, принадлежащих различным типам данных и, возможно, связанных между собой. Термин постоянно означает, что данные базы данных не являются собственностью никакой отдельной программы и могут поочередно ( или одновременно) использоваться различными программами без своего повторного описания. [19]
Перегруженные функции обычно используются для выполнения сходных операций над различными типами данных. [20]
Перегруженные функции обычно используются для выполнения сходных операций над различными типами данных. Программист пишет единственное определение шаблона функции. Основываясь на типах аргументов, указанных в вызовах этой функции, C автоматически генерирует разные функции для соответствующей обработки каждого типа. Таким образом, определение единственного шаблона определяет целое семейство решений. [21]
Перегруженные функции обычно используются для выполнения похожих операций над различными типами данных. Если же для каждого типа данных должны выполняться идентичные операции, то более компактным и удобным решением является использование шаблонов функций - возможности, появившейся в C сравнительно недавно. При этом программист должен написать всего одно описание шаблона функции. Основываясь на типах аргументов, использованных при вызове этой функции, компилятор будет автоматически генерировать объектные коды функций, обрабатывающих каждый тип данных. [22]
Создание нового атрибута является сложной задачей, включающей операции над различными типами данных. Для того чтобы эта задача была понятна эксперту, необходимо осуществить ее структурирование. Во-первых, механизм схем осуществляет декомпозицию индивидуальных типов данных на отдельные независимые подзадачи. Во-вторых, сеть схем обеспечивает общую организацию типов данных, определяя понятную последовательность тем. В-третьих, слоты и слот эксперты представляют многие соглашения о типах данных, что позволяет системе автоматизировать выполнение ряда операций, значительно упрощая общую задачу. В-четвертых, соответствие между типами данных и объектами области позволяет представить диалог в виде, понятном эксперту. [23]
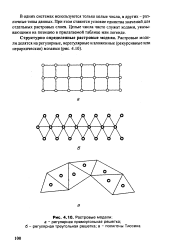 |
Растровые модели. [24] |
В одних системах используются только целые числа, в других - различные типы данных. При этом ставится условие единства значений для отдельных растровых слоев. Целые числа часто служат кодами, указывающими на позицию в прилагаемой таблице или легенде. [25]
Для сокращения избыточности производится объединение одинаковых по смыслу, но имеющих различный тип данных в единую БД с приведением к общему, стандартизованному виду. Процесс объединения данных, используемых различными пользователями, в одну общую БД называется интеграцией базы данных. [26]
В ПЛ / 1 имеются разнообразные средства для описания и обработки различных типов данных. В программе могут быты использованы арифметические, строковые данные и данные управления программой. Арифметические данные могут быть представлены не -; сколькими способами: они могут быть десятичными, двоичными, с фиксированной или плавающей точкой, для них может быть указана разрядность. [27]
Напишите программу, которая использует операцию sizeof для определения числа байтов различных типов данных в используемой вами системе компьютера. Напишите результат в файл data-size, dat, чтобы позднее его можно было распечатать. [28]
Важно, чтобы выбранные структуры данных были достаточно выразительны для представления различных типов данных. Однако если система ограничена единственной структурой представления, большая часть информации в полученной в результате базе знаний может оказаться явно не представленной, и это затрудняет понимание и модификацию базы знаний другими исследователями или пользователями. Одной из проблем построения представления в виде правил, используемого в системе PUFF, было то, что типичные совокупности данных трудно описать в виде правил. Все правила имеют один и тот же фермат посылок и действий, и все одинаково трактуются обрабатывающими программами системы. Это упрощает обработку, но в то же время порождает многие трудности представлений, которые уже обсуждались. [29]
В то же время вычисления в системе естественным образом распределяется между различными типами данных. [30]
Страницы: 1 2 3 4