Файл - индекс
Cтраница 1
Файл индексов позволяет осуществлять прямой доступ к записям данных основного файла с помощью терминов классификации. [1]
Пусть файл индекса хранится в известной совокупности блоков и требуется найти запись ( у2, Ь), такую, что иа покрывает заданное значение ключа Vi. Этот метод целесообразно применять только для небольших индексов, поскольку весь индекс должен вызываться в основную память. [2]
 |
Сортированный индексированный файл динозавров. [3] |
С помощью файла индекса определяем местоположение четвертого блока файла динозавров и обнаруживаем, что этот блок также заполнен. Поэтому создаем новый блок, первоначально содержащий только запись платеозавра, и помещаем его между третьим и четвертым блоками. [4]
В некотором смысле файл индекса подобен любому другому файлу с ключом, и фактически мы можем воспользоваться тем, что в файле индекса записи никогда не являются закрепленными указателями из другого места. [5]
При использовании для адресации файла индекса поиск в основном производится в нем, а не в файле. В системах пакетной обработки, как правило, используются только основные индексы, так как многочисленные группы запросов могут быть собраны и отсортированы таким образом, чтобы в процессе одного последовательного просмотра записей можно было получить нужную информацию. [6]
Чтобы установить связь или восстановить отсутствующие файлы индексов или заметок, выполните описанные ниже действия. [7]
Комплекс файлов тезауруса состоит из файла индексов, файла ссылок и файла структур и содержит совокупность элементов тезауруса, а именно: дескрипторы, синонимы, нотации систематики, а также связи между элементами тезауруса. [8]
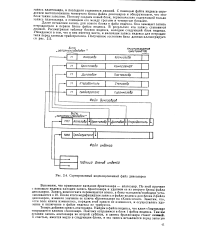 |
Сортированный индексированный файл динозавров. [9] |
Далее вставляем запись для нового блока в файл индекса. Она замещает запись птеродактиля в первом блоке файла индекса. В результате эта запись становится лишней. Рассматривая таблицу блоков индекса, находим следующий блок индекса. Убеждаемся в том, что в нем имеется место, и включаем запись индекса для птеродактиля перед записью трайсератопса. [10]
Запросы указанного типа исключают некоторые способы организации файлов индекса. Например, было бы неудобно использовать для них организацию хешированных файлов, рассмотренную в разд. [11]
Существует, однако, важное различие между файлами индекса и обсуждаемыми обычными файлами. Вероятно, кроме выполнения операции включения, удаления и модификации над файлами индекса, нам потребуется получать ответы на запросы следующего вида: при заданном значении ключа D. Таким способом мы находим блок Ь главного файла, содержащий запись со значением ключа vlt поскольку файл индекса с гарантией является сортированным. [12]
Записи главного файла могут быть закрепленными, но записи файла плотного индекса никогда таковыми не являются. [13]
Если i j меньше, чем первое значение ключа в файле индекса ( заметим, что это значение содержится во второй записи индекса), то требуемой записью индекса является первая запись. Следуем по указателю в выбранной записи индекса и попадаем на первый блок искомого участка. Для того чтобы найти запись с ключом v1, просматриваем этот и другие блоки участка, соединенные с ним цепью. [14]
Чтобы найти, модифицировать или удалить некоторую запись главного файла, нужно осуществить сначала поиск в файле плотного индекса, который указывает блок главного файла, гдд - находится требуемая запись. Далее следует читать этот блок главного файла и пере. Таким образом, выполняются еще два доступа к блокам в дополнение к доступам, необходимым для поиска в файле плотного индекса. [15]
Страницы: 1 2 3 4