Индексно-последовательный файл
Cтраница 2
Для индексно-последовательных файлов с блокированными записями в область ключа блока заносится ключ последней входящей в этот блок записи. Положение ключа в записи и его длина определяются описателями KEYLOC и KEYLENGTH оператора DECLARE, в котором описан файл. [16]
Обработка индексно-последовательных файлов включает типовые операции загрузки файла, корректировки, прямой и последовательной выборки. Далее приводится описание практически используемых на языке ПЛ / 1 алгоритмов и отдельных макрокоманд методов доступа, функции которых поясняются в примерах. [17]
 |
Корректировка индексно-последовательного файла. [18] |
Загрузку индексно-последовательного файла можно осуществлять в несколько приемов, однако при каждой дозагрузке необходимо предусматривать автоматическую проверку факта, что ключ первой дозагружаемой записи по значению больше ключа последней загруженной записи. [19]
Организация индексно-последовательного файла может быть очень простой, если в файл не должны включаться новые записи. Разновидности индексно-последовательных методов доступа отличаются в основном именно способами включения и удаления записей. [20]
Для индексно-последовательных файлов с неблокированными записями, кроме полей самих записей, можно описать поля области ключа и использовать их в программе точно так же, как и поля записей. В этом случае указываются номера начальной и конечной позиции описываемого пол я в области ключа. Перед номерами позиции записывается К - признак того, что поле является полем области ключа. [21]
После создания индексно-последовательного файла исходные данные помещаются в так называемую первичную область, напоминающую обычный последовательный файл. В момент закрытия файла система автоматически создает необходимые индексы. Когда добавляются новые записи, операционная система не реорганизует весь файл, а вставляет новую запись в соответствующее ее ключу место на дорожке, продвигая оставшиеся записи к концу. В результате последняя запись выталкивается с дорожки и переносится в область переполнения. Последняя может располагаться на каждом цилиндре для записей, поступающих именно с этого цилиндра, или предусматривается общая независимая область переполнения, в которую поступают записи со всех цилиндров. [22]
Начальное формирование индексно-последовательного файла называется загрузкой. Исходным файлом для загрузки служит последовательный файл, в записи которого выделено поле, которое в индексно-последовательном файле становится ключом. [23]
Чтение записей индексно-последовательного файла осуществляется разными операторами в зависимости от метода доступа. [24]
 |
Структура цилиндра диска индексно-последовательного файла. [25] |
При создании индексно-последовательного файла все записи файла помещаются в основную область. В область переполнения перемещаются записи, для которых не хватило места в основной области при добавлении в файл новых записей. [26]
Рассмотрим создание индексно-последовательных файлов на примере создания варианта файла PERECH. Структура записей файла описана в 10.1.2. Файл PERECH создается на основании карточного файла INPUT. [27]
Процесс описания индексно-последовательного файла достаточно громоздкий, поэтому обычно используется аппарат стандартных меток. Стандартная метка DSCB2 специально предназначена для хранения информации для нндексно-последователыюго файла. [28]
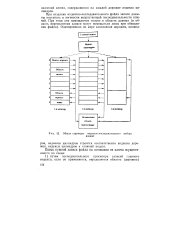 |
Общая структура индексно-последовательного набора. [29] |
При создании индексно-последовательного файла записи должны поступать в логически возрастающей последовательности ключей. [30]
Страницы: 1 2 3 4