Имя - данные
Cтраница 1
Имена данных должны быть уникальны в пределах записи. [1]
Имена данных с номерами-уровней 01 или 77 никогда не могут быть уточнены, так как они не могут принадлежать какой-либо другой группе. [2]
Имена данных, записей, отчетов и файлов представляют собой слова, определяемые программистом в соответствующих статьях описания в разделе данных; имена процедур определяются в заголовках параграфов и секций в разделе процедур. Если в форматах языка используется термин имя-данного, он представляет слово, которое не может ни уточняться, ни индексироваться, если в правилах для этого формата нет специального разрешения. [3]
Имя данных - это слово, которое содержит по меньшей мере один буквенный символ. Следовательно, в указанном выше перечне число 34598 - это слово, которое, однако, не может быть использовано в качестве имени данных. [4]
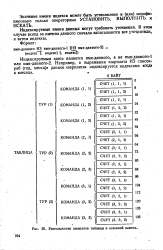 |
Расположение элементов таблицы в основной памяти. [5] |
Индексируемые имена данных могут требовать уточнения. В этом случае вслед за именем данного сначала записываются все уточнители, а затем индексы. [6]
Поскольку имена данных в КОБОЛе могут быть длиной до 30 литер, надо выбирать имена, несущие как можно больше информации об элементах данных. Следует избегать произвольно выбранных сокращений и аббревиатур. Такие сокращения, как EOF для конца файла ( end-of - file) или YTD для текущего года ( уear - to-date), общеприняты и однозначны. Однако сокращение ИНВ-НО неоднозначно ( что это - инвентарный номер или инвестиционный номер. Сокращений типа СВУР для сверхурочный следует избегать, поскольку даже его автор может легко забыть, что оно обозначает. Каждый, кто впервые сталкивается с такими сокращениями, никогда сразу не поймет их смысла. [7]
Вместо имен данных в указанных арифметических операторах могут стоять числовые литералы, но не на тех местах, на которых должно присутствовать имя результата. [8]
Литералы и имена данных, не являющиеся индексными данными, которые участвуют в сравнениях с именами индексов, должны представлять целые положительные числа. [9]
При уточнении имени данных следует помнить о том, что это можно сделать с помощью любого имени данных более высокого уровня, но только так, чтобы при этом не возникло неоднозначности. [10]
Определение каждого имени данных утомительно для программиста, но обеспечивает защиту от ошибок. [11]
При использовании имени данных оно должно иметь значение, которое положительно и меньше 32768; в противном случае оператор PERFORM выполнен не будет. Указанные в операторе процедуры выполняются указанное число раз. Типичным примером может служить сложение последовательностей чисел. [12]
В любом случае имена данных должны быть высокомнемоничными, чтобы обеспечить самодокументируемость описания данных. [13]
Список данных содержит имена данных, которым присваиваются значения, выделяемые из входного потока символов. В списке форматов перечисляются форматы, по которым осуществляется редактирование элементов потока для формирования значений данных. Элементы в списках данных и форматов отделяются друг от друга запятыми. [14]
В некоторых случаях имена данных определяют подэлемен-ты группы данных. Например, элементы ДЕНЬ, МЕСЯЦ и ГОД могут быть подэлементами элемента ДАТА. Для обеспечения возможности приписывания групповых имен в процедурах должна быть предусмотрена команда ГРУППА. Во время редактирования могут использоваться индивидуальные имена элементов данных ( как они указаны), но после завершения процесса редактирования автоматизированные процедуры должны иметь дело только с групповым именем. [15]
Страницы: 1 2 3