Среднее число - бита
Cтраница 1
 |
Альтернативный код дЛя ДИБП в примере. [1] |
Среднее число бит на символ для этого кода также равно 2.21. Следователь. Кроме того, назначение О верхнему переходу 1 нижнему ( менее вероятному) переходу выбрано произвольно. Мы можем прос поменять местами 0 и 1 и получить еще эффективный код, удовлетворяющий префиксно. [2]
Среднее число HI бит, употребляемых на символ первоначального сообщения, легко оценить. [3]
Значит, среднее число бит. [4]
Предположим также, что среднее число бит информации, попадающих на каждую букву, такое же, как и в английском языке. Вычислите расстояние единственности для зашифрованного гавайского сообщения, если ключевая последовательность состоит из случайной перестановки 12 букв алфавита. [5]
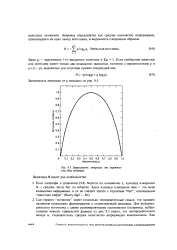 |
Зависимость энтропии от вероятности ( два события. [6] |
Если логарифм в уравнении (9.8) берется по основанию 2, единица измерения Я - среднее число бит на событие. [7]
Когда говорится о поведении кода переменной длины, массу информации можно получить из знания среднего числа бит. В кодовом присвоении переменной длины некоторые символы будут иметь длины кодов, превосходящие среднюю длину, в то время как некоторые будут иметь длину кода, меньшую средней. Может случиться, что на кодер доставлена длинная последовательность символов с длинными кодовыми словами. Кратковременная скорость передачи битов, требуемая для передачи этих символов, будет превышать среднюю скорость передачи битов кода. Если канал ожидает данные со средней скоростью передачи, локальный избыток информации должен заноситься в буфер памяти. К тому же на кодер могут быть доставлены длинные модели символов с короткими кодовыми словами. Кратковременная скорость передачи битов, требуемая для передачи этих символов, станет меньше средней скорости кода. В этом случае канал будет ожидать биты, которых не должно быть. По этой причине для сглаживания локальных статистических вариаций, связанных с входным алфавитом, требуется буферизация данных. [8]
Среднее число бит на отсчет зависит от вероятностного распределения амплитуды сигнала и установленных уровней ограничения. Для данного числа бит уровни ограничения, при которых достигается максимальное отношение сигнал / шум, вообще говоря, отличаются от полученных в разд. [9]
Предположим также, что оставшиеся 90 нажатий клавиш равновероятны. Определите среднее число бит, требуемое для кодирования этого алфавита с использованием кода Хаффмана переменной длины. [10]
Поскольку информация разрешает неопределенность, энтропия является средним количеством неопределенности, разрешенной с использованием алфавита. Она также представляет собой среднее число бит на символ, которое требуется для описания источника. В этом смысле это также нижняя граница, которая может быть достигнута с помощью некоторых кодов сжатия данных, имеющих переменную длину. Действительный код может не достигать граничной энтропии входного алфавита, что объясняется множеством причин. Это включает неопределенность в вероятностном соответствии и ограничения буферизации. [11]
Код Хаффмана ( Huffman code) [20] - это свободный от префикса код, который может давать самую короткую среднюю длину кода п для данного входного алфавита. Самая короткая средняя длина кода для конкретного алфавита может быть значительно больше энтропии алфавита источника, и тогда эта невозможность выполнения обещанного сжатия данных будет связана с алфавитом, а не с методом кодирования. Часть алфавита может быть модифицирована для получения кода расширения, и тот же метод повторно применяется для достижения лучшего сжатия. Эффективность сжатия определяется коэффициентом сжатия. Эта мера равна отношению среднего числа бит на выборку до сжатия к среднему числу бит на выборку после сжатия. [12]
Код Хаффмана ( Huffman code) [20] - это свободный от префикса код, который может давать самую короткую среднюю длину кода п для данного входного алфавита. Самая короткая средняя длина кода для конкретного алфавита может быть значительно больше энтропии алфавита источника, и тогда эта невозможность выполнения обещанного сжатия данных будет связана с алфавитом, а не с методом кодирования. Часть алфавита может быть модифицирована для получения кода расширения, и тот же метод повторно применяется для достижения лучшего сжатия. Эффективность сжатия определяется коэффициентом сжатия. Эта мера равна отношению среднего числа бит на выборку до сжатия к среднему числу бит на выборку после сжатия. [13]
Страницы: 1