Данные - файл
Cтраница 1
Данные файла STREAM рассматриваются как непрерывный поток символов. Записи, введенные в буфер, разделяются на составляющие элементы, редактируются во внутреннее представление. [1]
Группирование данных файла БД представляет собой подбор записей с одинаковыми значениями полей в один блок. По умолчанию сгруппированные блоки данных располагаются по возрастанию чисел для числовых полей или ASCII-кодов для символьных полей. Этот порядок можно изменить на обратный, введя альтернативный оператор упорядочивания. Для выполнения группирования выбирается позиция Group by после предварительной установки курсора в соответствующую графу шаблона файла. [2]
Способ адресации данных файла, принятый в ИНМОС, позволяет иметь прямой и быстрый доступ к файлам. Такая возможность усиливается кэшированием диска, позволяющим хранить в памяти некоторые наиболее часто используемые блоки. [3]
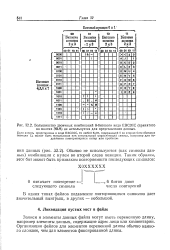 |
Большинство двоичных комбинаций 8-битового кода EBCDIC ( принятого во многих ЭВМ не используется для представления данных. [4] |
Записи и элементы данных файла могут иметь переменную длину, например элементы данных, содержащие адрес лица или комментарии. Организация файлов для элементов переменной длины обычно намного сложнее, чем для элементов фиксированной длины. [5]
Однако информация о структуре данных файла низкого уровня присутствует только в ПП, которая его непосредственно обрабатывает. Поэтому на данном уровне отсутствует независимость прикладных программ от данных. [6]
 |
Иерархия данных. [7] |
Большинство фирм используют для хранения данных много различных файлов. Например, компании могут иметь файлы начисления заработной платы, файлы счетов, по которым необходимо получить деньги ( списки сумм, причитающихся с клиентов), файлы инвентаризации, а также многочисленные файлы других типов. Группа связанных файлов иногда называется базой данных. [8]
Конечно, в большинстве случаев все данные файла не помещаются в запись MFT, поэтому этот атрибут, как правило, является нерезидентным. Рассмотрим теперь, как в файловой системе NTFS отслеживается расположение нерезидентных атрибутов, в частности данных. [9]
При операции чтения наблюдается обратное: данные файла предварительно считываются в буфер и по требованию процесса передаются в его область памяти. [10]
Конечно, в большинстве случаев все данные файла не помещаются в запись MFT, поэтому этот атрибут, как правило, является нерезидентным. Рассмотрим теперь, как в файловой системе NTFS отслеживается расположение нерезидентных атрибутов, в частности данных. [11]
Логической единицей отчета, аналогичной записи данных файла, является группа отчета. Группа отчета обычно представляет собой одну или несколько печатных строк. Каждая группа отчета относится к одному из следующих типов: заголовок отчета, заголовок страницы, управляемый заголовок, фрагмент, управляемая концовка, концовка страницы, концовка отчета. [12]
Атрибут PRINT указывает на то, Что данные файла будут выводиться на печать. Для этого каждая запись файла дополняется байтом служебной информации, обеспечивающей управление устройством печати. [13]
Атрибут PRINT указывает на то, что данные файла будут выводиться на печать. Для этого каждая запись файла дополняется байтом служебной информации, обеспечивающей управление устройством печати. [14]
Положительным качеством здесь является непрерывное расположение всех данных файла, что повышает эффективность его последовательной обработки. По этой причине он применяется в основном для файлов на магнитных лентах. [15]
Страницы: 1 2 3 4