Кодированные данные
Cтраница 2
 |
Прибор изме-рительный в виде клещей. [16] |
Прибор измерительный с регистрацией в коде - регистрирующий прибор, осуществляющий регистрацию измерительной информации в виде кодированных данных. [17]
 |
Схема наполнения и опорожнения проточной кюветы для инфракрасной спектрометрии. [18] |
Показания спектрометра - волновое число и коэффициент пропускания пробы - одновременно регистрируются с помощью двух циф-рокодирующих устройств. Необработанные кодированные данные хранятся в перфораторе Perkin Elmer DDR-IC. Обработка перфолент с результатами измерений производится на вычислительной машине. [19]
Кодовое управление применяется при вводе данных, так как исключает влияние величины на время ввода, что характерно для аналоговых величин. Время ввода кодированных данных определяется числом разрядов, и при выбранном диапазоне ( числе разрядов) не зависит от величин вводимых данных. [20]
 |
Диаграмма структуры поля 200 ( схема RUSMARCXML / Standard. [21] |
Предлагаемые решения были опробованы и показали высокую эффективность при разработке Сводного электронного каталога проекта Consensus omnium: корпоративная сеть библиотек Урала. В частности контроль корректности не прошли записи, в которых отсутствовали обязательные поля и подполя, а также записи, содержащие некорректные кодированные данные и недопустимые символы в идентификаторах подполей. [22]
На основе использования этой модели получены следующие оценки для кодирования одного слова английского текста: 11 8 бит и 9 8 бит. Кроме того, известно, что при кодировании на одну букву в английском тексте приходится от 1 до 2 бит. Если эти значения сопоставить с обсуждавшимся уже значением 8 бит на один знак азбуки ( слоговой), то и здесь можно ожидать аналогичных результатов. В связи с постоянным увеличением объема доступной оперативной памяти улучшаются и условия кодирования и обработки кодированных данных. Это связано прежде всего с возможностью более эффективной организации словарей, используемых для кодирования и декодирования. Для кодирования и уплотнения информации в японском языке предложено несколько методов. Однако здесь мы рассмотрим некоторые методы, которые предназначены для уплотнения главным образом текстов английского языка. [23]
Этот пример обращает внимание на потенциальную проблему, возникающую при использовании двоичной быстрой сортировки в реальных ситуациях: вырожденные разделения ( когда все ключи имеют одно и то же значение разряда, по которому производится разделение) могут встречаться довольно часто. Такая ситуация при сортировке малых чисел ( старшие разряды принимают значение 0), таких как в рассматриваемых нами примерах, не является чем-то необычным. Эта же проблема возникает при использовании ключей, состоящих из символов: например, предположим, что мы строим 32-разрядные ключи из четырех символов, каждый из которых представлен в стандартном 8-разрядном коде, объединяя их в единое целое. Тогда появление вырожденных разделений возможно в начальной позиции каждого символа, поскольку, например, все буквы нижнего регистра начинаются с одних и тех же битов для большинства кодов символов. Эта проблема является типовой по своим последствиям, с которыми приходится сталкиваться при сортировке кодированных данных, подобные проблемы возникают и в других видах поразрядной сортировки. [24]
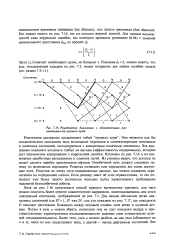 |
Решетчатая диаграмма с обозначенными расстояниями от нулевого пути. [25] |
Она является как бы символическим описанием всех возможных переходов и соответствующих начальных и конечных состояний, ассоциируемых с конкретным конечным автоматом. Эта диаграмма позволяет взглянуть глубже на выгоды ( эффективность кодирования), которые дает применение кодирования с коррекцией ошибок. Из рисунка видно, что декодер не может сделать ошибку произвольным образом. Ошибочный путь должен следовать одному из возможных переходов. Решетка позволяет нам определить все такие доступные пути. Получив по этому пути кодированные данные, мы можем наложить ограничения на переданный сигнал. Если декодер знает об этих ограничениях, то это позволяет ему более просто ( используя меньшее Е / Л / о) удовлетворять требованиям надежной безошибочной работы. [26]
Страницы: 1 2