Поисковый массив
Cтраница 1
Поисковый массив организуется по прямой системе, в которой описания документов ( сокупность кодов дескрипторов) следуют вместе с номерами соответствующих документов. [1]
Поисковый массив ( рис, 5), который составляет ИПС. Как же происходит поиск в данной системе. [2]
Поисковый массив документов ИПС, по аналогии с фактографическими системами, обычно также называется базой данных. Он чаще всего не содержит непосредственно текстов документов. Наиболее широко распространенные ИПС - библиографические системы - оперируют, как правило, только библиографическими описаниями и значительно реже рефератами или аннотациями документов. [3]
Затем из поискового массива извлекаются поисковые карты с дескрипторами, соответствующими дескрипторам поискового образа запроса. [4]
Адресная часть поискового массива служит для перехода от кодов элементов сообщений / Сэ к адресам А0 их первых вхождений в массив сообщений. В адресной части записаны коды всех попарно-различных элементов сообщений и соответствующие им адреса АО. В рассматриваемом примере предполагается, что поиск в адресной части будет вестись цепным способом, а в качестве признаков для формирования ассоциативных цепочек будут служить свертки кодов элементов сообщений. [5]
При дополнении поискового массива новыми сообщениями выполняются следующие еперации. Сначала для элементов нового сообщения в массиве А ищутся адреса Ле. Если сообщение не содержит новых элементов, то найденные адреса записываются в первую свободную ячейку массива Б, а адреса участков этой ячейки заносятся на прежние места храпения адресов АО. Если сообщение имеет в своем составе новые элементы, то для них вместо адресов Ай в свободную ячейку массива Б заносятся признаки конца ассоциативных цепочек, а адреса участков этой ячейки и коды новых элементов заносятся в свободные ячейки массива А. Ячейки массива А подключаются к ассоциативным цепочкам, соответствующим сверткам кодов новых элементов. Сообщения исключаются из поискового массива путем затирания содержимого ячеек, представляющих эти сообщения, и переноса хранившихся в них отсылочных адресов на такие участки ячеек массива Б, где ранее были записаны адреса участков освобождаемых ячеек. [6]
База данных состоит из поискового массива, формируемого по результатам индексирования реферативной информации, и информационного массива, содержащего записи текстов рефератов. База данных реализована на средствах вычислительной техники типа ЕС. [7]
Если нужно исключить элементы информации из поискового массива, то достаточно затереть только их коды, оставляя без изменения адресную часть массива. Тогда, аряду с общим резервом памяти, а участке В для отдельных ассоциативных цепочек будут образованы частные резервы, которые могут быть использованы для записи новых элементов. Ячейки участков Б и В поискового массива, освобождающиеся в результате исключения из него отдельных элементов информации, а также предусмотренные с самого начала резервы памяти этих участков могут быть объединены в общий резерв памяти путем создания ассоциативной группы свободных ячеек. [8]
Положительные свойства прямого и инверсного способов организации поисковых массивов сочетаются в узловом ассоциативно-адресном способе представления информации. Описания документов представляются в виде узлов адресных отсылок. Каждый узел содержит столько отсылочных адресов, сколько предметных рубрик имеется в описании соответствующего документа. В процессе поиска просматриваются только такие описания документов, которые содержат хотя бы одну предметную рубрику из запроса. [9]
Известные трудности создает и очень широкая тематика поискового массива документов. В многоотраслевых собраниях документов неоднозначность ключевых слов проявляется шире, чем в узкоотраслевых собраниях. Для устранения этой неоднозначности приходится увеличивать объем тезауруса и усложнять его структуру. [10]
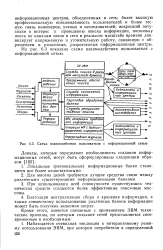 |
Схема взаимодействия пользователя с информационной сетью. [11] |
При использовании всей совокупности существующих технических средств создаются более эффективные поисковые массивы. [12]
В двухконтурных ИПС поисковые образы документов хранятся в отдельном поисковом массиве, что позволяет ускорить поиск адресов документов. Таким образом, общий процесс поиска необходимой информации состоит из двух этапов. На первом этапе в массиве поисковых признаков отыскивают адрес необходимого документа, на втором - в массиве документов выполняют поиск и выборку документа по найденному адресу. Двухконтурные ИПС обычно реализуются в системах на микрофильмах и в АИПС. [13]
Комплекс Поиск - выдача осуществляет автоматизированный поиск документов в прямом поисковом массиве, формирует файл, управляющий выдачей, и проводит выдачу найденных документов на АЦПУ как по основным запросам, так и по дублирующим. [14]
В заключение следует заметить, что в рассмотренном примере деление поискового массива на адресную часть и массив элементов информации является функциональным. В действительности поле памяти ЭВМ не расчленяется на два непересекающихся участка. Благодаря наличию отсылочных адресов и кодов связи элементы участков Б и В на рис. 5.1 могут располагаться на общем поле памяти в произвольном порядке. Выделение отдельного поля памяти необходимо только для участка А адресной части поискового массива. [15]
Страницы: 1 2 3 4