Большая база - данные
Cтраница 4
Более широкие возможности системы MYCIN в решении проблем проистекают от двух факторов: большой набор правил, которые используются для формирования гипотез и способов подтверждения их истинности, и большая база данных, в которой хранится информация о микроорганизмах, медикаментах и лабораторных тестах. [46]
Можно отметить, что и эта характеристика не дает исчерпывающего представления о возможности машины, если принять во внимание, что на высокопроизводительные ЭВМ все в большей степени возлагают функции управления большими базами данных, связанные с большим количеством информационно-логических операций и операций обмена данными с внешней памятью. [47]
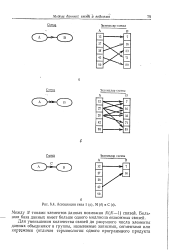 |
Ассоциации типа 1 ( а, М ( б и С ( в. [48] |
Между N типами элементов данных возможно N ( N-1) связей. Большая база данных имеет больше одного миллиона возможных связей. [49]
Проектирование без данных представляет собой длительный и трудоемкий процесс. Проектирование больших баз данных, включающих 500 и более элементов, обычно длится несколько месяцев, а в некоторых случаях растягивается даже на годы. До настоящего времени проектирование баз данных остается скорее искусством, чем наукой. Основными ресурсами проектировщика баз данных служат его собственные интуиция и опыт, причем качество получаемого при этом результата весьма сомнительно. Во многих готовых системах слабым местом оказывается структура базы данных. Основная проблема проектирования заключается в определении назначения элементов данных. Но даже после решения этой проблемы трудно получить удовлетворительные структуры данных из-за сложности процесса структурирования. База данных должна обеспечивать получение необходимых данных и их эффективную обработку. Плохо спроектированная база данных может затруднить процесс прикладного программирования и потребовать реализации более сложной логики в программах, чем это необходимо для получения требуемой инфор мации. [50]
Пользователей базы данный можно разделить на три категории: конечные пользователи ( те, что вводит и извлекает данные), программисты ( те, кто пишет прикладные программы ( АЛ 13 applications program) обработки данных ] и администраторы базы данных ( D. В случае больших баз данных может быть несколько конечных пользователей, программистов и администраторов, тогда как в случае небольших баз данных функции конечного пользователя, программиста ядминистра тора базы данных может выполнять один человек. [51]
 |
Инвертированный список, представленный битовой картой. [52] |
К недостаткам этой системы относятся довольно большие затраты времени на составление инвертированных индексов и их обновление, причем эти затраты возрастают с увеличением объема базы данных. Поэтому для очень больших баз данных часто может оказаться лучшим последовательный доступ, при котором используют, например, специальные аппаратные средства для ускорения выборки данных посредством выполнения параллельных операций поиска и чтения записей. [53]
Применительно к большой базе данных наиболее важная проблема, которую следует рассмотреть заключается в поддержке индексов для данных. То есть, как кратко упоминалось в разделе 12.7, предполагается, что элементы, образующие нашу таблицу символов, хранятся где-то в статической форме, а наша задача состоит в построении структуры данных с ключами и ссылками на элементы, которая позволяет быстро ссылаться на данный элемент. Например, телефонная компания может хранить информацию о клиентах в огромной статической базе данных при наличии нескольких индексов, возможно, использующих различные ключи, для ежемесячных оплат, для обработки ежедневных транзакций, периодических обращений к клиентам и т.п. Для очень больших наборов данных индексы имеют первостепенное значение: в основном, копии основных данных не создаются не только потому, что невозможно выделить дополнительный объем памяти, но и потому, что желательно избежать проблем, связанных с подержанием целостности данных в условиях присутствия нескольких копий. [54]
Главными требованиями, предъявляемыми к методам извлечения знаний, являются эффективность и масштабируемость. Работа с очень большими базами данных требует эффективности алгоритмов, а неточность и, зачастую, неполнота данных порождают дополнительные проблемы для извлечения знаний. Нейронные сети имеют здесь неоспоримое преимущество, поскольку именно они являются наиболее эффективным средством работы с зашумленными данными. Действительно, заполнение пропусков в базах данных - одна из прототипических задач, решаемых нейросетями. [55]
При распределенном хранении очень больших баз данных их поддержка осуществляется набором ЭВМ. [56]
Страницы: 1 2 3 4