Множество - кортежь
Cтраница 3
Мы уже видели, как функции типа COUNT, MIN и МАХ применяются к множествам. Эти функции позволяют вычислять значения на множествах кортежей. [31]
В этом случае ар ( R) есть множество кортежей /, принадлежащих R, таких, что при подстановке t - ro компонента t вместо любого вхождения номера I в формулу F для всех i она станет истинной. Например, а23 ( R) обозначает множество кортежей, принадлежащих R, второй компонент которых больше третьего компонента. В то же время ff1 smith v i - Jones ( R) есть множество кортежей, принадлежащих R, первый компонент которых имеет значение Smith или Jones. Как и в проекции, формула в селекции может ссылаться на столбцы по именам, а не по номерам, если столбцы отношения именованы. Заметим также, что константы в формулах должны быть заключены в кавычки. Это позволяет отличать их от номеров или имен столбцов. [32]
Интересным новшеством являются также процедуры-селекторы. Введение таких селекторов позволяет обобщить процесс выделения множеств кортежей отношений и сделать его более удобным для пользователей. [33]
Сопоставим предложенные даталогические понятия с понятиями моделей данных из части 2 настоящей книги. Например, в реляционной модели данных ядру соответствует множество кортежей, определяющее текущее состояние отношений, описанных в схеме. Виртуальные сообщения соотносятся с множеством кортежей отношений, выводимых с помощью реляционной алгебры. Любое неизвестное сообщение или не рассматривается, или рассматривается как ложное. И наконец, понятие забытых сообщений не используется, так как база данных содержит только текущие кортежи. Некоторые другие данные могут выступать в качестве элементов данных контрольных точек и журнала. Тем не менее они не есть часть базы данных и, следовательно, формально не представлены в модели данных. [34]
В селекции на горизонтально фрагментированном отношении принимают участие распределенные по ВМ кортежи. Параллельное исполнение селекции заключается в чтении каждой ВМ своего резидентного множества кортежей и сравнения для каждого кортежа значения атрибута кортежа с требуемым значением. [35]
Оглавление таблицы может содержать только различимые переменные, константы и пробел. Как и каждому реляционному выражению, каждой таблице может быть сопоставлено множество кортежей, которое называется значением таблицы. Оценивание р для Т есть отображение множества 5 на множество констант. [36]
В PIQUE можно ссылаться на подзапросы с помощью ключевого слова in, определяющего соединение значения кортежной переменной, которое задается окном, и отношения - результата подзапроса. Таким образом, in обозначает теоретико-множественное отношение принадлежности некоторого кортежа ( или его части) множеству кортежей, полученных в результате подзапроса. Переменные подзапроса локальны по отношению к нему и никак не связаны с одноименными переменными объемлющего запроса. [37]
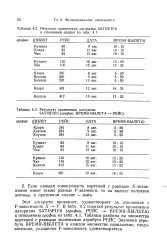 |
Результат применения алгоритма SATISFIES к отношению график из.| Результат применения алгоритма. [38] |
Этот алгоритм проверяет, удовлетворяет ли отношение г F-зависимости Х - - Y. В табл. 4.2 показан результат применения алгоритма SATISFIES ( график, РЕЙС - ВРЕМЯ-ВЫЛЕТА) к отношению график из табл. 4.1. Таблицы разбиты на множества кортежей с равными значениями атрибута РЕЙС. Значения атрибута ВРЕМЯ-ВЫЛЕТА в каждом множестве одинаковые, следовательно, указанная F-зависимость удовлетворяется. [39]
Группы, формируемые в результате выполнения процедур первого этапа анализа информационных требований пользователей, в общем случае представляют собой ненормализованные отношения, в информационных составах которых возможно наличие повторяющихся элементов данных. На втором этапе анализа при выделении ключей и атрибутов в группах данных исходные данные ( множество областей значений ( доменов)) информационных элементов групп и множество кортежей значений элементов, формируемые в диалоге с разработчиками БД, изменяются таким образом, что в каждом кортеже R фиксируется только одно значение из областей определения Oi каждого информационного элемента группы. Таким образом, каждая группа drj на этапе подготовки исходной для процедур выделения ключей и атрибутов информации представляется в виде двумерной матрицы Т, в столбцах которой расположены конкретные значения элементов групп ( при наличии повторяющихся элементов отдельные значения остальных могут дублироваться), а в строках - кортежи значений информационных элементов. [40]
Представление информации о конструируемых или подлежащих изготовлению объектах в виде таблиц кодированных сведений, предложенное авторами в работах [26, 28], в настоящее время стало общепринятым. Несмотря на кажущуюся разницу, все они являются модификациями одной общей идеи, заложенной в таблицах кодированных сведений, а именно таблицы кодированных сведений ( ТКС) представляют собой множества однотипных кортежей реквизитов, описывающих элементы конструкций. [41]
Таким образом, значения рубричной или сложной характеристик могут быть представлены в виде некоторой ОХТ. У этой ОХТ может быть либо линейной, либо рубричной, либо сложной в зависимости от свойств соответствия ( 10) и от того, является ли область прибытия этой характеристики множеством литералов или множеством кортежей одинаковой длины. [42]
На самом же деле расходы памяти сокращаются, поскольку в этом случае уменьшается дублирование значений элементов данных. Это легко показать, сравнивая рис. 14.1 с рис. 14.5 и рис. 14.3 с рис. 14.4. Нередко третья нормальная форма предпочтительна и с точки зрения использования процессора, так как при обработке данных, представленных не в третьей нормальной форме, приходится считывать и перезаписывать множество кортежей. [43]
Ниже рассматривается система ADE - результат совместных усилий Университета Калабрии и фирмы ENIDATA ( Италия. Система ADE поддерживает простое расширение чистого Дейталога, включающее отрицание и объекты. Объект образуется множеством кортежей, расположенных в нескольких отношениях и имеющих один и тот же уникальный идентификатор объекта. Программы Дейталога транслируются в Пролог с сохранением семантики неподвижной точки Дейталога. При этом обеспечивается безопасность реализации, позволяющая получать множество всех ответов. Для компиляции используется мини-магический метод, представляющий собой вариант метода магических множеств. Рассматривается также и метод магического подсчета. [44]
Предположим, что задано отношение и значения по крайней мере тех атрибутов, которые образуют ключ этого отношения и реализующего его файла. Следовательно, процедура удаления для соответствующей организации может быть применена непосредственно к лежащему в основе файлу. Большинство систем допускает удаление множества кортежей даже в том случае, когда не задан ключ. При этом необходимо просматривать полный файл независимо от используемой стандартной организации. [45]
Страницы: 1 2 3 4