Нормализация - данные
Cтраница 1
Нормализация данных служит для уменьшения избыточности информации в таблицах базы данных. Предварительно данные, которые будут храниться в таблицах базы данных, анализируются и разбиваются на несколько связанных таблиц. Существуют специальные способы нормализации данных, которые в итоге приводят к пяти нормальным формам таблиц базы данных. В данном случае мы не будем заниматься глубоким изучением этого вопроса ( для этого есть специальная литература), а рассмотрим процесс нормализации на конкретном примере. [1]
Нормализация данных в реляционных СУБД приводит к созданию множества связанных между собой таблиц. В результате выполнение сложных запросов неизбежно приводит к объединению многих таблиц, что существенно увеличивает время отклика. Проектирование хранилища данных подразумевает создание денормали-зованной структуры данных ( допускается избыточность данных и возможность возникновения аномалий при манипулировании данными), ориентированной в первую очередь на высокую производительность при выполнении аналитических запросов. Нормализация делает модель хранилища слишком сложной, затрудняет ее понимание и ухудшает эффективность выполнения запроса. [2]
АГК используется после нормализации данных. [3]
К модели данных предъявляются определенные требования ( нормализация данных), которые призваны обеспечить компактность и непротиворечивость хранения данных. Основная идея нормализации данных - каждый факт должен храниться в одном месте. Это приводит к тому, что информация, которая моделируется в виде одной стрелки в модели процессов, может содержаться в нескольких сущностях и атрибутах в модели данных. Информация о таких стрелках находится в одних и тех же сущностях. Следовательно, одной и той же стрелке в модели процессов могут соответствовать несколько сущностей в модели данных и, наоборот, одной сущности может соответствовать несколько стрелок. [4]
На этой стадии полезно отметить ограничения на нормализацию данных. Базы данных редко следуют ясной политике в этом вопросе; однако хорошая стратегия предполагает полное и четкое нормирование базы данных, ограничиваемое только требованиями производительности. Следует обеспечить точное соответствие третьей нормальной форме, а затем проводить денормализацию базы данных только при необходимости. Эта стратегия подходит для любого случая. [5]
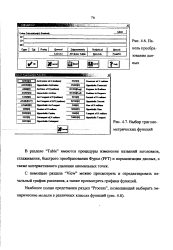 |
Панель преобразования данных.| Выбор тригонометрических функций. [6] |
В разделе Table имеются процедуры изменения названий заголовков, сглаживания, быстрого преобразования Фурье ( FFT) и нормализации данных, а также интерактивного удаления аномальных точек. [7]
В отличие от алгоритма ЛА, алгоритм КАА оперирует с истинными температурами и измененной шкалой времени, поэтому он не обеспечивает нормализации данных. Например, изображения обоих коэффициентов АйяА отражают эффекты неоднородного нагрева ( рис. 5.12, а, б) дереве ( См. Наилучшая видность всех шести дефектов имеет место в изображении коэффициента А2 ( рис. 5.12, б), тогда как изображение коэффициента А6 на рис. 5.12, в характеризуется весьма искаженными отпечатками дефектов, иллюстрируя такую важную черту изображений полиномиальных коэффициентов как изменение знака сигналов от дефектов, расположенных на различных глубинах. [8]
В основе теории реляционных баз данных ( далее слово реляционные будем опускать и говорить просто базы данных), которая была заложена Коддом в 70 - х годах, лежат такие понятия, как таблица, отношение, запись ( строка), поле ( столбец), нормализация данных, индекс. [9]
 |
Иллюстрация четвертой нормальной формы. [10] |
В результате нормализации все взаимосвязи данных становятся правильно определеными, исключаются аномалии при оперировании данными, модель данных становится легче поддерживать. Однако часто нормализация данных не ведет к повышению производительности ИС в целом. После приведения структуры данных к третьей нормальной форме ( рис. 2.2.49) информация о сотруднике содержится уже в четырех таблицах. [11]
К модели данных предъявляются определенные требования ( нормализация данных), которые призваны обеспечить компактность и непротиворечивость хранения данных. Основная идея нормализации данных - каждый факт должен храниться в одном месте. Это приводит к тому, что информация, которая моделируется в виде одной стрелки в модели процессов, может содержаться в нескольких сущностях и атрибутах в модели данных. Информация о таких стрелках находится в одних и тех же сущностях. Следовательно, одной и той же стрелке в модели процессов могут соответствовать несколько сущностей в модели данных и, наоборот, одной сущности может соответствовать несколько стрелок. [12]
Консольная таблица не может быть связана с таблицей факта. Она используется для нормализации данных в таблицах размерности. Нормализация данных полезна при моделировании реляционной структуры, но она уменьшает эффективность выполнения запросов к хранилищу данных. В размерной модели главной целью является обеспечение высокой эффективности просмотра данных и выполнения сложных запросов. [13]
Многие термины, например вибрации, могут быть также применены к наблюдаемым выходным данным. Это целесообразно, так как для сравнения и поиска данных требуются нормализация данных посредством их аналогичного описания и применение идентичных единиц измерения. Это требование относится в равной мере как к регулируемым, так и нерегулируемым факторам. [14]
Консольная таблица не может быть связана с таблицей факта. Она используется для нормализации данных в таблицах размерности. Нормализация данных полезна при моделировании реляционной структуры, но она уменьшает эффективность выполнения запросов к хранилищу данных. В размерной модели главной целью является обеспечение высокой эффективности просмотра данных и выполнения сложных запросов. [15]
Страницы: 1 2