Обработка - статистические данные
Cтраница 2
Для обработки опытных и статистических данных в Maple имеется пакет stats. Он содержит в себе команду leastsquare, которая позволяет определять параметры различных зависимостей с помощью метода наименьших квадратов. [16]
 |
Возникновение профессиональных заболеваний, Германия, 1980 - 93 гг.| Инфекционные заболевания, признанные профессиональными, Германия, 1980 - 93. [17] |
Результаты обработки статистических данных по профессиональным заболеваниям - Важная функция статистики по профессиональным заболеваниям касается выявления профессиональных заболеваний по прошествии времени. В таблице 32.11 приведены симптомы возможных профессиональных заболеваний, число всех признанных случаев профессиональных заболеваний и назначенных пенсий, а также статистика летальных исходов в промежутке с 1980 по 1993 годы. Необходимо заметить, что работать с приведенными данными достаточно сложно, поскольку существует заметная разница в определениях и критериях. Следует также учитывать, что начиная с 1991 года цифры охватывают территорию всей объединенной Германии, в то время как более ранние сведения относятся только к ФРГ. [18]
Результаты обработки статистических данных о колебании коэффициентов неравномерности отбора воды по часам суток расчетного дня хч и суткам расчетного сезона ( месяца) хм приведены в работах автора. [19]
При обработке статистических данных необходимо соблюдать предъявляемые к ним требования: сопоставимости, динамичности и объективности. В результате анализа должны быть выявлены нерациональные затраты реагентов, вызванные отступлением от принятой технологии, режимов работы, рецептур и составов, несоблюдением требований по качеству расходуемых химреагентов и обрабатываемого сырья, а также транспортные и складские потери материалов, которые не должны включаться в нормы. [20]
При обработке статистических данных, как правило, эксцесс и асимметрию получают отличными от нуля. Если исследование причин отклонений показывает, что асимметрия и эксцесс эмпирического распределения случайны, то следует остановиться на нормальном законе распределения. В тех случаях, когда отклонения обусловлены характером процесса или специфическими, но часто встречающимися в практике строительства условиями проведения работ, следует подобрать такое теоретическое распределение, которое аппроксимирует статистические данные более удачно, чем нормальный закон распределения. [21]
При обработке статистических данных, полученных в испытаниях, осуществляется проверка однородности результатов. Для решения вопроса о том, учитывать или нет резко выделяющиеся данные, существует несколько критериев. Чаще всего используют критерий Романовского. [22]
При обработке статистических данных определяют вероятностные характеристики ошибок как функции времени работы устройств. К этим характеристикам относят вид распределения, среднее время между отказами или сбоями, кратность ошибок, наличие пачек и др. Эти характеристики являются исходными данными для выбора метода введения избыточности и расчета надежности проектируемой ЭВМ. [23]
При обработке статистических данных обычно приходится исключать резко выделяющиеся величины, искажающие статистические характеристики. Поэтому фактическое число наблюдений обычно следует принимать несколько больше установленного расчетом. [24]
При обработке статистических данных, полученных в результате натурных наблюдений и экспериментальных исследований по характеристикам прочности, нагрузкам и размерам сечений важную роль играют выборочные распределения. [25]
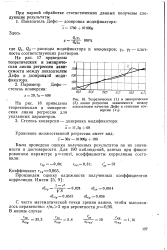 |
Теоретическая ( 1 и эмпирическая ( 2 линии регрессии зависимости между показателем качества Дефо и степенью конверсии ( х. [26] |
При парной обработке статистических данных получены следующие результаты. [27]
Наблюдения и обработка статистических данных по разрушениям сварных стыков показывают, что механизм и временной фактор разрушений зависят от марки сталей труб. [28]
Была выполнена обработка статистических данных по результатам анализа причин возникновения отказов. [29]
Рассмотрим примеры обработки статистических данных с помощью суперпозиции распределений. [30]
Страницы: 1 2 3 4