Анализ - алгоритм
Cтраница 3
Мы закончили анализ алгоритма М; новая черта, которая характеризует этот анализ, - это введение теории вероятностей. [31]
Проведенный выше анализ алгоритмов диспетчеризации с динамическими приоритетами показал, что эти алгоритмы являются дальнейшим обобщением рассмотренных ранее алгоритмов с фиксированными приоритетами и обладают по сравнению с последними рядом существенных с точки зрения возможностей организации вычислительного процесса преимуществ. Эти преимущества заключаются в наличии целого ряда регулируемых параметров, выбор которых позволяет при проектировании алгоритмов ЦВМ получить необходимые значения времени задержки в обслуживании заявок различных типов. [32]
В рамках анализа алгоритмов по трудоемкости мы можем считать, что обслуживающие фрагменты программной реализации ( ввод, проверка и вывод) являются общими или эквивалентными для разных алгоритмов решения данной задачи. Такой подход приводит к необходимости анализа только непосредственного алгоритма решения. При этом предполагается размещение исходных данных и результатов в оперативной памяти, включая в это понятие как собственно оперативную память, так и кэш память, регистры и буфера реального процессора. Таким образом, множество элементарных операций, учитываемых в функции трудоемкости, не включает операции ввода / вывода данных на внешние носители. [33]
Основные трудности анализа алгоритма в среднем случае связаны как с выяснением значений трудоемкости для конкретных входов, так и с определением вероятности их появления. В связи с этим задача вычисления / А ( п) для алгоритмов класса NPR является достаточно трудоемкой. Эти методы могут быть использованы и для получения функции трудоемкости алгоритмов в среднем случае. [34]
На основании анализа алгоритма решения задачи устанавливают необходимый порядок вычислений. При этом для повышения эффективности программы повторяющиеся части формул обозначают дополнительными переменными и записывают в виде самостоятельных формул. Составляют логическую схему ( обычно в виде блок-схемы) последовательности выполнения вычислений. [35]
Хотя при анализе алгоритмов мы предпочитаем равномерный весовой критерий в силу его простоты, мы должны отвергнуть его, если пытаемся установить нижние границы на временную сложность. РАМ с равномерным весом вполне разумна, когда рост чисел по порядку не превосходит размера задачи. Но, как мы уже говорили, при использовании РАМ в качестве модели размер чисел заметается под ковер, и вряд ли можно получить полезные нижние оценки. Для логарифмического веса, однако, верна следующая теорема. [36]
Один из способов анализа алгоритма сортировки состоит в том, чтобы подсчитать число инверсий, отличающее начальное состояние списка от отсортированного списка. Каждая перестановка элементов в алгоритме уменьшает количество инверсий по крайней мере на одну. Если, например, пузырьковая сортировка обнаружила в результате сравнения пару соседних элементов, идущих в неправильном порядке, то их перестановка уменьшает количество инверсий в точности на единицу. То же самое справедливо и для сортировки вставками, поскольку сдвиг большего элемента на одну позицию вверх приводит к уничтожению инверсии, образованной сдвигаемым и вставляемым элементами. Поэтому в пузырьковой сортировке и сортировке вставками ( обе сложности O ( JV2)) всякое сравнение может привести к удалению одной ( или менее) инверсии. [37]
Первый шаг при анализе алгоритма состоит в определении абстрактных операций, на которых основан алгоритм, чтобы отделить анализ от реализации. Так, например, мы отделяем изучение того, сколько раз одна из реализаций алгоритма union-find запускает фрагмент кода i a [ i ], от подсчета, сколько наносекунд требуется для выполнения этого фрагмента кода на данном компьютере. Для определения реального времени выполнения программы на заданном типе компьютера требуются оба упомянутых элемента. Первый из них определяется свойствами алгоритма, последний - свойствами компьютера. Такое разделение зачастую позволяет сравнивать алгоритмы таким способом, который не зависит от определенной реализации или от определенного типа компьютера. [38]
Роль входных данных в анализе алгоритмов чрезвычайно велика, поскольку последовательность действий алгоритма определяется не в последнюю очередь входными данными. [39]
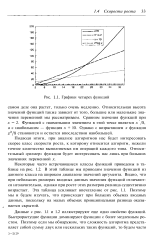 |
Графики четырех функций. [40] |
Подводя итоги, при анализе алгоритмов нас будет интересовать скорее класс скорости роста, к которому относится алгоритм, нежели точное количество выполняемых им операций каждого типа. [41]
Иногда ( обычно при анализе алгоритмов сопряженных направлений) говорят о / ( - шаговой скорости сходимости. [42]
Вычислительная сложность - это направление анализа алгоритмов, которое занимается фундаментальными ограничениями, могущими возникнуть при анализе алгоритмов. Общая цель заключается в определении времени выполнения для низкой производительности лучшего алгоритма для данной задачи с точностью до постоянного множителя. Эта функция называется сложностью задачи. [43]
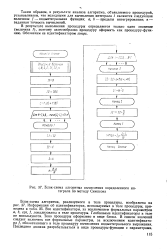 |
Блок-схема алгоритма вычисления определенного интеграла по методу Симпсона. [44] |
Таким образом, в результате анализа алгоритма, объявляемого процедурой, устанавливаем, что исходными для вычисления интеграла / являются следующие величины: f - подынтегральная функция; а, Ь - пределы интегрирования; е - заданная точность вычислений. [45]
Страницы: 1 2 3 4