Процессорный блок
Cтраница 3
В системах типа ОКМД параллелизм и перестраиваемость существуют только на уровне однотипных команд одной программы: текущая команда с общего устройства управления тиражируется по всем процессорным блокам, и те из них, которые снабжены соответствующими. [31]
Такие системы обладают параллелизмом на уровне команд нескольких программ, но в них отсутствует параллелизм выполнения команд каждой отдельно взятой, одной программы: на независимых процессорных блоках одновременно выполняется по одной команде из независимых программ. Поэтому такие системы не обладают лерестраиваемо-стью на уровне команд ни нескольких программ, ни одной программы. Это приводит к тому, что при выполнении в устройстве управления служебных команд ( управления, пересылок, переходов и пр. [32]
Автомат содержит регистр занятости процессорных блоков РПБ, регистр занятости буферов ( регистров PI и Р2) процессорных блоков РБ, таблицу номеров процессорных блоков ТПБ, регистр-распределитель процессорных блоков РР, приоритетное устройство ПУ, анализирующее приоритеты устройств управления ( приоритеты задач и ветвей), таблицу приоритетов устройств управления, распределитель выборки устройств управления РВ. PI и Р2 нет данных); шина 2 признака занятости буферов ПБ ( по ней устанавливается 1 в г - м разряде регистра РБ, если пуст хотя бы один из регистров Р и Р2 в UEi); шина 3 для передачи приоритетов ветвей ( задач) из УУ в ПУ; шина 4 для передачи номера УУ, которому разрешен доступ к РП; шина 5 для передачи сигнала в УУ нет готовых к выполнению команд; шина б для передачи сигнала о наличии команд, готовых к выполнению ( из выбранного УУ последовательно передается столько единиц, сколько готовых к выполнению команд имеется в данном УУ); шина 7 для передачи номера, предоставляемого ПБ, из таблицы ТПБ в УУ. Для простоты на рис. 4.9 изображена магистральная структура связей между УУ и РП: магистраль S используется для передачи кодов команд и операндов в ПБ, а магистраль 9 - для передачи результатов вычислений в УУ. [33]
В более общем плане мы будем понимать под пере-страиваемостью МВС степень ее способности к динамическому перераспределению каждого типа параллельных ресурсов ( памяти, устройств ввода-вывода, устройств управления, процессорных блоков) между программами и их параллельными фрагментами, осуществляемому операционной системой или аппаратурным путем по указаниям в программе или автоматически, путем анализа хода выполнения программ в соответствии с их текущими требованиями на ресурсы. [34]
Прототипом источников заявок в рассматриваемой модели являют-гя устройства управления ( УУ) МВС, выполняющие обработку программ задач или их фрагментов и обеспечивающие выполнение скалярных и векторных команд в процессорных блоках. Поток обращений каждого УУ формируется как объединение нескольких потоков заявок, причем некоторые из потоков являются независимыми между собой. Наличие такого суммарного потока в УУ является следствием параллелизма процессов обработки и выполнения команд: опережающего чтения из ОП команд обрабатываемой программы, независимого расчета адресов и чтения из ОП скалярных и векторных операндов, пересылки в ОП результатов параллельного выполнения команд в процессорных блоках, промежуточных обращений к ОП при обработке косвенных адресов и пр. [35]
Аппарат ОСВ дает программисту возможность оперировать с векторами и матрицами с любым разумным количеством элементов вне зависимости от реального объема вычислительных ресурсов МВС, скрывая от программиста и от транслятора объем буферной памяти в УУ и число процессорных блоков МВС. [36]
Структурная схема процессора ЭВМ ЕС-1030 приведена на рис. 7.6. Все арифметические и логические операции выполняются в арифме-тическо-логическом блоке БАЛ. Управление работой процессорных блоков производится блоком микропрограммного управления БМПУ. [37]
Методика синтеза процессорных блоков конвейерного сложения с ускоренным переносом в СОК при применении нейронной сети рекурсивной редукции может быть представлена следующим образом. [38]
Мы предлагаем три модификации процессорного блока, различающихся по мощности. Кроме того, вам предлагается большое количество опций и аксессуаров, в выборе которых помогут наши специалисты. [39]
УУ и одновременного завершения выполнения команд на двух и более ПБ равны нулю. Реально же устройства управления, как и процессорные блоки решающего поля, могут функционировать независимо по отношению друг к другу. [40]
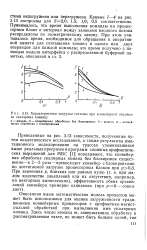 |
Характеристики загрузки системы при конвейерной обработке скалярных команд. [41] |
Кривые 1 - 4 на рис. 3.13 построены для 52 0; 1 5; 1 0; 0 5 соответственно. Принималось, что время выполнения команды на процессорном блоке и интервал между заявками входного потока распределены по геометрическому закону. При этом учитывалось время, необходимое для обращения к оперативной памяти для считывания команд и одного или двух операндов для каждой команды; это время получено с помощью модели интерфейса с распределенной буферной памятью, описанной в гл. [42]

В этой системе спекловая картина поля излучения из ОМИ регистрируется матрицей фотодиодов, подобранной таким образом, что каждый фотодиод регистрирует один светлый или один темный спекл. Электрический сигнал от каждого фотодиода первоначально поступает в процессорный блок, содержащий аналоговый элемент памяти и электрический перемножитель сигналов. Напряжение, накопленное на конденсаторе, соответствует начальному состоянию спекла. Поэтому перемножитель сигналов производит умножение текущего значения напряжения на величину запомненного ( опорного) напряжения. В результате, после суммирования сигналов от всех датчиков, на выходе системы формируется сигнал пропорциональный сигналу корреляции полей излучений из ОМИ. [44]
В первой фазе параллельно и независимо друг от друга работают п устройств управления. Во второй фазе параллельно и независимо работают т однотипных процессорных блоков. Функции распределения времени генерации и выполнения команд могут иметь различный вид. В соответствии с доводами, изложенными в § 2.4, будем считать, что время генерации команд в УУ и время выполнения команды в БП распределены по геометрическому закону. [45]
Страницы: 1 2 3 4