Ввод - документ
Cтраница 2
В описании компонентов ввода документа должна быть ровно одна строка с уровнем 01 без метки, с которой начинается собственное описание компонентов. Помеченных уровней 01 может быть несколько, по числу описываемых шаблонов, они могут отсутствовать, если в описании компонентов нет шаблонов. [16]
Типичными функциями таких систем являются ввод документов, в частности, с помощью средств их автоматического распознавания; их атрибутирование; поиск нужных данных; поддержка групповой работы над документами; разграничение прав доступа к документам; подготовка отчетов; маршрутизация документов, учет их движения; контроль исполнения предписываемых документами действий; автоматическое уведомление соответствующих лиц о состоянии документов и содержащихся в них директив и рекомендаций; планирование работ, связанных с прохождением документов. [17]
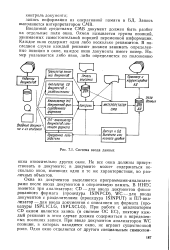 |
Система ввода данных. [18] |
Окна из документов выделяются программами-анализаторами после ввода документов в оперативную память. При работе с анализатором CD окном является запись ( в системе ОС ЕС), поэтому каждый реквизит в этом случае должен содержаться в определенных позициях записи. При вводе документов анализатором WC позиции, в которых находится окно, не играют существенной роли. [19]
В системе автоматизации персонифицированного учета застрахованных лиц массовый ввод документов, заполненных вручную, производится с помощью использования станции сканирования и распознавания ручных документов. [20]
Эта строка служит для задания имени описания компонентов ввода документа. Имя пишется с 7 - й позиции и имеет не более восьми символов. [21]
 |
Структура процесса ввода запросов и алгоритмическая схема поиска информации в системе ОРДИНАТА. [22] |
С помощью вводного устройства системы ( ВВУ) производится ввод Документов в систему, которым присваиваются адресные и порядковые номера. [23]
Ввод документов производится в три этапа ( рис. 7.1): ввод документа с внешнего носителя в оперативную память. [24]
В делопроизводстве сканер может потребоваться в сочетании с программой распознавания текста для ввода документов. Такая программа автоматически распознает текст и не требует его набора с клавиатуры, чем облегчает трудоемкий процесс ввода текстов. [25]
Возможно, что в будущем синтаксический и семантический анализ текстов, а также ввод документов, осуществляемый сейчас обычно опытными специалистами-индексаторами, будет заменен некоторыми средствами анализа, которые будут получены при помощи машины на основе уже имеющихся массивов документов. [26]
Эти системы позволяют выполнять все виды операций, связанных с анализом данных, начиная от ввода документов в различной форме и заканчивая обработкой и хранением результатов исследований. [27]
Под исполнительной частью системы подразумеваются те программные блоки, которые предназначены для выполнения расчетов, ввода документов к печати выходных форм. [28]
На эти вопросы желательно получить следующие ответы: получаются устойчивые кластеры, не зависящие от порядка ввода документов, с равномерным распределением документов по кластерам, причем число этих кластеров оптимально с точки зрения эффективности и скорости работы системы. В частности, учитывая очень большие объемы документальных БД, как правило, нежелательно допускать пересечение кластеров. [29]
Тезаурус, дескрипторы в котором связаны друг с другом родовидовыми и ассоциативными отношениями, позволяет при вводе документов в ИПС ( или при формулировании поисковых предписаний) дополнять поисковые образы этих документов ( или соответствующие поисковые предписания) избыточными дескрипторами, то есть такими, которые в логическом смысле стоят выше и ( или) ниже основных дескрипторов или могут по какой-либо ассоциации употребляться вместе с ними. Благодаря этому всегда может быть учтена специфика информационного запроса ( например, требуемая широта и точность информационного поиска) и обеспечен достаточно точный перевод любого информационного запроса на ИПЯ. Подробно процедура лексикографического редактирования поисковых образов и предписаний при их вводе в ИПС будет описана в одном из следующих разделов. [30]
Страницы: 1 2 3 4