Рубрицирование
Cтраница 1
Рубрицирование выполняется по некоторому решающему правилу, учитывающему как важность терминов в документе, так и их веса для рубрик. [1]
Задача рубрицирования в первоначальной редакции ставится следующим образом. Пусть имеется одноуровневый рубрикатор, состоящий из j рубрик. [2]
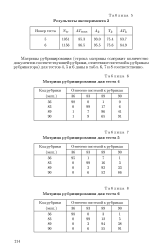 |
Матрица рубрицирования для теста 5. [3] |
Матрицы рубрицирования ( строка матрицы содержит количество документов соответствующей рубрики, отнесенное системой к рубрикам рубрикатора) для тестов 4, 5 и б даны в табл. 6, 7 и 8 соответственно. [4]
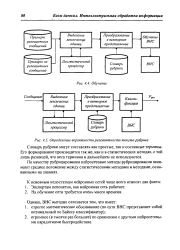
Процесс рубрицирования разбивается на два этапа. Первым из них является выделение понятий из текста, которое можно представить как процесс распознавания, основывающийся на использовании данных из базы определений. Решение о наличии понятия в тексте принимается путем вычисления справедливости выражения, определяющего понятие, относительно данного текста. Если выражение справедливо, то считается, что понятие присутствует в тексте. Кроме того, если в определении понятия присутствуют экспертные веса, то вычисляется вес или вероятность появления данного понятия в обрабатываемом тексте с учетом частоты встречаемости фраз в тексте сообщения. [5]
 |
Процесс рубрицирования. [6] |
Идея статистического рубрицирования состоит в определении степени соответствия терминологического портрета документа и терминологического портрета рубрик на основе статистических характеристик субъектов сравнения. Под терминологическим портретом документа понимают совокупность наиболее важных терминов, содержащихся в тексте документа. [7]
Для быстрого рубрицирования энциклопедических статей разработана система автоматизированной рубрикации, реализованная в виде специального рабочего места редактора-лингвиста. [8]
 |
Определение вероятности релевантности текста рубрике. [9] |
По качеству рубрицирования нейросетевые методы рубрицирования занимают среднее положение между статистическими методами и методами, основанными на знаниях. [10]
Принято качество рубрицирования оценивать следующим образом. Иногда вводят интегральный критерий качества AT, представляющий собой среднее геометрическое ( или среднее арифметическое) точности и полноты. [11]
Суть процесса рубрицирования в рамках данного подхода состоит в выделении из текста опорных дескрипторов и отношений между ними с последующим сопоставлением их с описаниями рубрик. [12]
Сходство задач рубрицирования множества документов Мд и формирования обучающей совокупности М0б очевидно: как одна, так и другая, вне зависимости от подхода к ее решению, включает в качестве основной компоненты подзадачу отнесения документа из заданного множества документов к некоторой рубрике. Вместе с тем, имеют место и определенные различия. В задаче рубрицирования документов множества Md исходными являются требования полноты и точности выделения рубрик. При формировании обучающей совокупности MOQ требуется лишь точность выделения документов. Обязательным является также условие, согласно которому совокупность MOQ должна отражать все разнообразие представленных в документах М0 аспектов проблемы Р, значимых для проводимого пользователем исследования. Еще одно требование состоит в том, что документы М0 не должны содержать лишней информации, и, следовательно, являясь документами рубрики г, одновременно принадлежать каким-либо другим рубрикам рубрикатора R. Таким образом, полноты поиска документов, принадлежащих г, в этом случае не требуется: необходимо включение в состав М0б лишь некоторой части таких документов. [13]
Для многих приложений рубрицирования важно правильно оценить достоверность отнесения документа к той или иной рубрике. [14]
Более высокие результаты рубрицирования в тестах 5 и б, по сравнению с равновесным тестом 4, объясняются эффектом перенасыщения, поскольку объем обучающего материала в тесте 4 превышает оптимальный. [15]
Страницы: 1 2 3