Рубрицирование
Cтраница 2
Основой нейросетевых методов рубрицирования текстов является использование нейронной сети ( НС) в качестве обучаемого классификатора. Считается, что в наличии имеется подборка примеров текстов, каждый из которых помечен как релевантный или нерелевантный определенной рубрике. Задача НС, обученной на этих примерах, состоит в определении степени релевантности любого нового текста данной рубрике. [16]
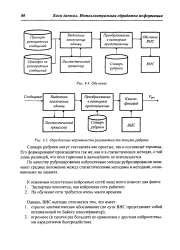 |
Определение вероятности релевантности текста рубрике. [17] |
По качеству рубрицирования нейросетевые методы рубрицирования занимают среднее положение между статистическими методами и методами, основанными на знаниях. [18]
Преимуществами данного подхода являются высокое качество рубрицирования и высокое быстродействие на тех текстовых потоках, для которых они проектировались. [19]
На основе предложенных теоретических выкладок авторами была реализована экспериментальная система рубрицирования текстовых документов ТЕРМИН-5. Практика работы с ТЕРМИН-5 показала, что она в условиях самых разных рубрикаторов и обучающих выборок работает без провалов, давая удовлетворительное качество рубрицирования. В качестве дальнейшего развития метода предполагается его адаптация к многотемным обучающим выборкам. [20]
Эксперименты показали, что неверный выбор OQ может резко снизить качество рубрицирования. Это понятно и из априорных соображений. Если характеристических терминов мало, то, очевидно, многие короткие документы не будут содержать их в достаточном для уверенной их идентификации количестве, следовательно, будет падать полнота рубрицирования. Наоборот, если характеристических терминов слишком много, то неизбежны пересечения рубрик по терминам и использование для идентификации недостаточно надежных терминов, что будет приводить к необоснованному присвоению лишних рубрик, следовательно, будет падать точность рубрицирования. [21]
В современных исследованиях по данной проблеме выделяют два основных подхода [18]: рубрицирование, основанное незнаниях, и рубрицирование, основанное на обучении по примерам. [22]
Представляется, что наиболее актуальной является постановка задачи полностью автоматического рубрицирования, когда система рубрицирования сама, по обучающей выборке текстов, настраивается на рубрикатор и вырабатывает решающее правило отнесения документа к той или иной рубрике. [23]
Дело в том, что лексико-статистический подход, по своей сути, не дает 100 % надежности рубрицирования по обучающей выборке, поскольку он ориентирован не на интерполяцию примеров ( как, например, метод нейронных сетей [2]), а на поиск интегральных признаков ( характеристических терминов), применение которых к обучающим документам вовсе не обязано точно рубрицировать каждый из них. Поэтому имеется следующая возможность: создать несколько словарей-рубрикаторов, полученных для разных порогов OQ, и, применяя их для рубрицирования обучающей выборки, выбрать оптимальный из них по критерию наилучших результатов рубрицирования. [24]
В современных исследованиях по данной проблеме выделяют два основных подхода [18]: рубрицирование, основанное незнаниях, и рубрицирование, основанное на обучении по примерам. [25]
Главным недостатком данной группы методов является более низкое по сравнению с методами, основанными на знаниях, качество рубрицирования. [26]
В соответствии с основными принципами организационно-технологической структуры в АСИНИТ выделяются следующие основные службы: экспедиция, техническая обработка; бесперфорационный ввод; редактирование; смысловая обработка ( индексирование, рубрицирование); сопровождение интегрального ввода; микрофильмирование; обработка на ЭВМ; администратор базы данных; подготовка статистических обзоров; информационные фонды; электрография; диспетчеризация; справочно-информационная служба; сопровождение обмена и изданий; подготовка изданий; подготовка аналитических обзоров. [27]
Под тезаурусом понимается иерархическая сеть понятии и отношений между ними. Тезаурус может быть разработан независимо от какой-либо системы рубрицирования. В качестве вариантов ( синонимов или эквивалентов) дескрипторов в тезаурусе встречаются именные и глагольные группы, отдельные существительные, прилагательные или глаголы. [28]
Дело в том, что лексико-статистический подход, по своей сути, не дает 100 % надежности рубрицирования по обучающей выборке, поскольку он ориентирован не на интерполяцию примеров ( как, например, метод нейронных сетей [2]), а на поиск интегральных признаков ( характеристических терминов), применение которых к обучающим документам вовсе не обязано точно рубрицировать каждый из них. Поэтому имеется следующая возможность: создать несколько словарей-рубрикаторов, полученных для разных порогов OQ, и, применяя их для рубрицирования обучающей выборки, выбрать оптимальный из них по критерию наилучших результатов рубрицирования. [29]
На основе предложенных теоретических выкладок авторами была реализована экспериментальная система рубрицирования текстовых документов ТЕРМИН-5. Практика работы с ТЕРМИН-5 показала, что она в условиях самых разных рубрикаторов и обучающих выборок работает без провалов, давая удовлетворительное качество рубрицирования. В качестве дальнейшего развития метода предполагается его адаптация к многотемным обучающим выборкам. [30]
Страницы: 1 2 3