Кодовое слово
Cтраница 1
Кодовое слово должно быть присвоено каждому имеющемуся или вновь образуемому сегменту. Таким образом, сегменты второго типа состоят из кодовых слов. Так как кодовое слово может относиться не только к сегменту первого типа, но и к сегменту второго типа, то кодовые слова могут порождать иерархическую структуру, в которой каждое кодовое слово является узлом, от которого отходит ветвь дерева. Если кодовое слово обозначает сегмент первого типа, то на этом сегменте ветвь оканчивается и, следовательно, сегмент первого типа будет терминальным 1 ( оконечным), кодовые слова элементов второго типа порождают ветви, исходящие из данного узла. Совокупность всех терминальных сегментов охватывает все программные сегменты и все сегменты информационных массивов. Таким образом, каждому терминальному сегменту можно поставить в соответствие последовательность узлов-сегментов второго типа, в которых даны ссылки, приводящие, к указанному сегменту. При такой структуре информации о сегментах доступ к информационному сегменту наиболее просто может быть организован, как уже было указано в предыдущем параграфе, при помощи ассоциативной памяти, но можно организовать доступ также и при помощи косвенной адресации. Для облегчения работы каждое кодовое слово должно нести всю информацию, необходимую для поиска и размещения сегмента. [1]
Кодовое слово, далее, попадает на кодоразделительное устройство КРУ, которое направляет кодовую группу оь в декодирующее устройство ДУ. Там она преобразуется в исходный импульс, амплитуда которого пропорциональна величине сигнала в момент отсчета, попадающий в общую точку выходного распределителя PZ - При замыкании ключа т под воздействием кодово-адресной группы этот импульс попадает на от-й выход. [2]
Кодовое слово любого столбца таблицы декодирования является ближайшим кодовым словом ко всем прочим словам данного столбца. [3]
Тогда кодовое слово длиной тг соответствует концевому узлу, отстоящему от яруса порядка т на m - mf ребер. [4]
Каждое кодовое слово при таком кодировании можно представить последовательностью из r - log2 M - j двоичных символов, и если эти двоичные символы передаются надежно по каналу с шумом, то искажение между последовательностью адресата ( одним из кодовых слов) и последовательностью источника равно просто искажению, введенному при первоначальном кодировании. [5]
Если кодовое слово не содержит ошибок, то корректирующее число должно быть равно нулю. При наличии ошибки корректирующее число должно содержать номер ошибочного разряда. Введем первый контрольный разряд, которому присвоим нечетный порядковый номер и который установим при кодировании таким образом, чтобы сумма единиц всех разрядов с нечетными порядковыми номерами была равна нулю. [6]
Каждое кодовое слово состоит из четырех символов сообщения и четырех контрольных символов. Пусть это используется как код, обнаруживающий ошибки двоичного симметричного канала. [7]
Каждое кодовое слово определяется в терминах двух полиномов Мэттсона - Соломона, один из которых определяет левую часть кодового слова, а другой - правую. [8]
Каждое кодовое слово содержит 8 двоичных разрядов. [9]
Пусть кодовое слово длиной и разрядов имеет т информационных и k п - т контрольных разрядов. Корректирующее число длиной / с разрядов описывает 2 состояний, соответствующих отсутствию ошибки и появлению ошибки в J-M разряде. [10]
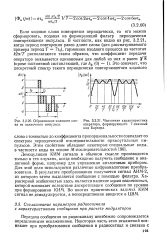 |
Образование кодового ело - [ IMAGE ] Частотная характеристика ва из одиночного импульса. оператора, формирующего 7-значный. [11] |
Если кодовое слово повторяется периодически, то его можно сформировать, подавая на формирующий фильтр периодически повторяющиеся импульсы. [12]
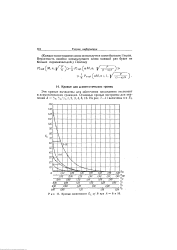 |
Кривые зависимости EL от R при А 8 и 16. [13] |
Каждое новое кодовое слово используется самое большее 1 / а раз. [14]
Пусть неизбыточное кодовое слово состоит из 0 ( информационных) символов. Для построения кода с коррекцией к ним добавляют k проверочных символов. Таким образом, кодовое еловой корректирующем коде имеет п п0 k позиций. [15]
Страницы: 1 2 3 4