Лучшая точка
Cтраница 2
Сказанное вовсе не означает, что множество Q содержит только лучшие точки. [16]
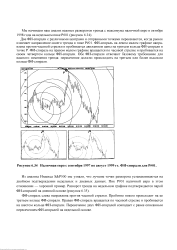 |
Наличная евро с сентября 1997 по август 1999 гг. ФИ-спирали для Р 01. [17] |
Из анализа Индекса S & P500 мы узнали, что лучшие точки разворота устанавливаются на двойном подтверждении недельных и дневных данных. [18]
Суть алгоритма 4.4 чрезвычайно проста - на каждой итерации в план добавляется лучшая точка из X, а затем из полученного плана удаляется худшая его точка. [19]
Следующим этапом метода крутого восхождения является выбор в качестве центра нового плана лучшей точки проведенных опытов. Далее проводится новый полный факторный эксперимент только для значимых параметров. Процедура крутого восхождения повторяется после проверки адекватности уравнения регрессии эксперименту. [20]
Теперь переходим ко второму шагу - сравниваем две новые точки деления, ищем лучшую точку, выбираем два отрезка вокруг нее, делим еще одной и вновь переходим ко второму шагу... В итоге, после какого-то измерения с номером N будет найдена такая точка X, которая попадет в интервал от ( Xmax-Q) до ( Xmax Q), где Хтах - аргумент, соответствующий абсолютному Fmax, a Q - абсолютная погрешность, которую мы считаем приемлемой. [21]
Если одному и тому же втулочному отношению соответствует более одной точки, то лучшая точка этой группы показана черным цветом. [22]
Переход к нулевому режиму осуществляется в случае, если на сфере С5 наименьшего радиуса не нашлось лучшей точки. [23]
Ясно, что, выбирая каждый раз точку произвольно, мы имеем шансы наткнуться и на самую лучшую точку. Но, позвольте - воскликнет возмущенный читатель - это же просто перебор. Да, конечно, это перебор, но перебор случайный, ибо произвольный выбор каждой точки и означает, что ее координаты назначаются равномерно) случайным выбором из всех допустимых в пределах области поиска значений. Разумно, однако, спросить, есть ли польза в переходе от перебора на сетке к случайному перебору. [24]
Когда найдена лучшая точка, к рассмотрению принимаем такие два целых соседних отрезка, один из которых находится справа от лучшей точки, а другой - слева. [25]
Значительность роли вектора градиента для НЛП не должна вызывать сомнений, поскольку, если дана некоторая неоптимальная точка, то с помощью градиента обычно можно найти лучшую точку. Однако прежде чем рассмотреть градиент, мы должны ввести понятие направления, так как градиент сам по себе является направлением. [26]
Суть процедуры ясна: в каждом новом цикле число точек измерения возрастает на одну и притом этот прирост приходится на ту область, где в предшествующем цикле обнаружена лучшая точка. [27]
Как уже отмечалось, если о виде целевой функции не существует никакой достоверной априорной информации, то можно рекомендовать первоначально провести оптимизацию во всей допустимой области с использованием случайных глобальных методов поиска с тем, чтобы далее вблизи одной ( или нескольких) найденных лучших точек уточнить результат с помощью одного из имеющихся в библиотеке методов локального поиска. [28]
Следует добавить, что при съемке широкоугольным объективом достаточно лишь немного изменить расстояние до объектов или направление съемки, чтобы взаимное расположение предметов, изображаемых на переднем плане, резко изменилось. Это упрощает выбор лучшей точки съемки, так как фотографу приходится передвигаться в пределах лишь небольшого пространства. В то же время при малейшем изменении точки съемки или положения фотоаппарата построение снимка изменяется настолько, что приходится заново оценивать все его особенности. [29]
Страницы: 1 2 3