Исходная выборка
Cтраница 2
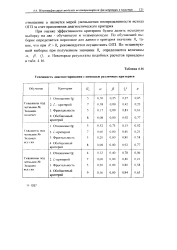 |
Успешность диагностирования с помощью различных критериев. [16] |
При оценке эффективности критериев будем делить исходную выборку на две - обучающую и экзаменующую По обучающей выборке определяется пороговое для данного критерия значение R, такое, что при R / рекомендуется осуществить ОПЗ. [17]
 |
Входные параметры процесса переработки темплена. [18] |
В результате проведенного таким образом предварительного анализа исходной выборки оказалось, что качество перерабатываемых партий материала оценивается только двумя сортами: вторым и третьим. [19]
Группа высоких значений составляла приблизительно треть от исходной выборки Испытуемые из этого кластера активно реагировал на ФС и изменение ее частоты, что особенно эко проявилось при работе с 5-ти секундными интервалами. Здесь значения первой попытки были иже второй, в дальнейшем приближаясь к среднему по кластеру ФС частотой 10 Гц значительно зеличивала разброс данных, а при воздействии частотой 20 Гц форма ответа приближалась к гходной, но с большим разбросом значений. [20]
Теперь есть все необходимое для нахождения медианы исходной выборки данных. Напомним, что при нечетном N медианой является средний элемент вариационного ряда. Если N четно, то средних элементов два и в качестве медианы принимают полусумму этих средних элементов. [21]
Из приведенного определения следует, что медиана разбивает исходную выборку на две равные по числу элементов группы, причем в первой группе все х - меньше медианы, а во второй - больше ее. Практическая реализация алгоритма выборочной медианы почти не требует вычислений, а основная работа затрачивается на сортировку исходных данных и построение вариационного ряда. Кроме того, этот метод устойчив к аномальным ошибкам в исходных данных, что делает его особенно эффективным там, где возможны сбои измерительной аппаратуры. [22]
Сопоставление вычисленных параметров позволяет принять гипотезу о нормальном распределении исходной выборки. [23]
N является средний член вариационного ряда, полученного из исходной выборки. [24]
X) содержит столько же информации о 9, как исходная выборка X. Свойство, заключающееся в том, что при проведении все большего числа наблюдений можно в конце концов получить всю информацию о 9, на языке теории информации выражается следующим образом. [25]
X) содержит столько же информации о Э, как исходная выборка X. Свойство, заключающееся в том, что при проведении все большего числа наблюдений можно в конце концов получить всю информацию о Э, на языке теории информации выражается следующим образом. [26]
Величины главных компонент получают путем умножения собственной матрицы S на нормированные значения X исходной выборки. [27]
Эта задача предусматривает предварительное ( или одновременное с процессом построения искомых регрессий) разбиение исходной выборки на однородные ( по условиям эксперимента) части и оценку функции регрессии отдельно для каждой такой части. [28]
Однако, наша задача состоит не в том, чтобы с абсолютной точностью аппроксимировать исходную выборку, то есть включить в математическую модель все наблюдающиеся особенности конкретной выборки, в том числе и те, которые в действительности носят случайный характер. Нам нужно найти всего несколько наиболее значимых гармоник, то есть гармоник, имеющих максимальную амплитуду. Для этого необходимо построить и проанализировать амплитудно-частотную характеристику разложения. [29]
Решение о наличии сигнала в наблюдаемой выборке принимается в том случае, если отношение правдоподобия для исходной выборки оказывается не меньше пороговой константы С. [30]
Страницы: 1 2 3 4