Вычисление - дисперсия
Cтраница 3
Рассмотрим несколько примеров вычисления дисперсии. Используем случайные переменные, описанные в предыдущем пункте, и вычисленные для них средние. [31]
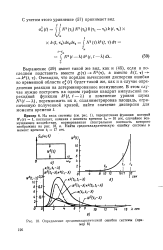 |
Определение среднеквадратической ошибки системы ( пример 8. [32] |
Очевидно, что порядок вычисления дисперсии ошибки во временной области а ( t) будет такой же, как и в случае определения реакции на детерминированное возмущение. [33]
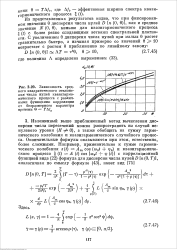 |
Зависимость среднего квадратического отклонения числа нулей квазигармонического процесса с различными функциями корреляции от безразмерного параметра времени в. [34] |
Изложенный выше приближенный метод вычисления дисперсии числа пересечений можно распространить на случай ненулевого уровня ( Н 0), а также обобщить на сумму гармонического колебания и квазигармонического случайного процесса. Окончательные формулы оказываются при этом, естественно, более сложными. [35]
Напомним, что при вычислении дисперсии, возводя в квадрат ошиб-и, мы тем самым делаем величины неотрицательными. Существует, однако, другой способ сделать их неотрицательными независимо от того, были ли ошибки первоначально отрицательными или положительными. Действительно, возьмем абсолютное значение ошибки ( модуль) и рассмотрим следующую весьма простую процедуру оценивания стандартного отклонения. [36]
В основу алгоритма ИСОМАД положено вычисление внутригруппо-вых дисперсий, центрами которых являются выборочные средние. Однако по сравнению с похожими другими алгоритмами ИСОМАД имеет преимущество - в нем содержится ряд эвристических процедур, участвующих в процессе итерации, резко повышающих эффективность алгоритма. В этом смысле он наиболее полно отвечает интуитивному представлению об итерационной кластеризации для широкого класса данных. [37]
Это свойство часто используют при вычислении дисперсии. [38]
Дело не в том, что само вычисление дисперсии представляет сложность, а в том, что этого нельзя сделать, не задав во всех деталях модель образования текста. Обычно для полного задания такой мо - Дели просто не хватает эмпирических данных. [39]
В качестве примера в табл. 3.2 приведено вычисление дисперсии по сгруппированным данным, полученным при сравнительном изучении двух аналитических методов. [40]
Если постулируется экспоненциальный закон надежности, то вычисление дисперсии по формуле ( 30 - 153) отнимает много времени, проще построить теоретическую функцию распределения и проверить сходимость эмпирической и теоретической кривых. [41]
В нижней части для сопоставления приведены результаты вычисления дисперсий ( вектор Sp) другим способом - с помощью матриц AR, BR эквивалентной формы Коши, введенных в разд. [42]
КФ берется положительным без знака абсолютного значения, поэтому вычисление дисперсий по КФ не встречает затруднений. [43]
Все четыре метода точны при отсутствии ошибок вычисления, но вычисление дисперсии при отсутствии вычислительной машины часто занимает много времени. [44]
Последнее выражение указывает на важность учета даже небольшой корреляции при вычислении дисперсии от выборки большого объема. [45]
Страницы: 1 2 3 4