Избыточные данные
Cтраница 4
 |
Экземпляр единичного отношения, в котором содержатся данные, приведенные на ( г и ( г. [46] |
В этом специальном случае одно отношение - это все, что требуется. Так как степень связи здесь 1: 1 и класс принадлежности является обязательным как для сущности ПРЕПОДАВАТЕЛЬ, так и для сущности КУРС, гарантируется однократное появление каждого значения нп и каждого значения нк в любом экземпляре отношения. Это значит, что отношение никогда не будет содержать ни пустой информации, ни повторяющихся групп избыточных данных. Ключ сущности ПРЕПОДАВАТЕЛЬ был избран в качестве первичного ключа для отношения, но также может быть использован ключ сущности КУРС. [47]

Сначала в GA1 применяются правила коррекции ошибок, описанные в конце разд. Затем GA1 определяет начальный набор ограничений для генератора, множество сегментов и множество мест рассечения ферментом, необходимые для построения молекул-кандидатов. Правила для построения такого списка сегментов здесь рассматриваться нами не будут, укажем лишь, что в них используются результаты оценки молекулярного веса и избыточные данные, поступающие в результате нескольких процессов усвоения. Затем начинается процесс генерации, осуществляемый путем комбинирование сегментов и мест рассечения и проверки того, что результат соот ветствует имеющимся данным. [49]
Переход от системы файлов, каждый из которых содержит один тип записи, к базе данных с разными типами записей и структурированными наборами данных дает множество преимуществ. Одним из них является значительное увеличение эффективности, обусловленное использованием для поиска всех записей с определенным значением ключа структурован-ных множеств данных одновременно с первичными и вторичными ключами. При использовании структурированных наборов данных можно исключить всю избыточную информацию, что приводит к уменьшению необходимого объема памяти. Есл № избыточные данные были специально сохранены, чтобы увеличить скорость поиска, то их можно использовать, чтобы убедиться, что обновление какого-либо значения в одной записи влечет за собой изменения во всех соответствующих записях. [50]
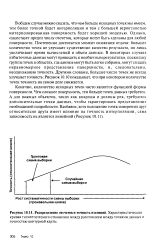 |
Распределение отсчетов и точность изолиний. Характеристическая кривая гипотетического отношения между расстоянием между точками данных и точностью контурной карты. [51] |
Однако, существует предел числу отсчетов, которые могут быть сделаны для любой поверхности. Постепенно достигается момент снижения отдачи: большее количество точек не улучшает существенно качество результата, но лишь увеличивает время вычислений и объем данных. В некоторых случаях избыточные данные могут приводить к необычным результатам, поскольку группы точек в областях, где данные могут быть легко собраны, могут создать неравномерное представление поверхности, и, следовательно, неодинаковую точность. Другими словами, большее число точек не всегда улучшает точность: Рисунок 10.10 показывает, что при некотором количестве точек точность на самом деле снижается. [52]
Всякий раз при вызове eval она генерирует один возможный ответ. Шаблон, ассоциированный с начальным запросом, используется для управления процессом. Эта функция применяется в предложении findall для того, чтобы все ответы могли быть собраны вместе в случае, если вопрос допускает несколько вариантов ответов. Остальные части предиката удаляют избыточные данные на выходе, затем компонуют его и распечатывают выходные данные. [53]
Внимание Access не предполагает, что вы хотите видеть дублирующиеся данные, когда разворачиваете вспомогательную таблицу данных. Использование команды Unhide Columns ( Показать столбцы) решает проблему лишь временно. Когда вы в следующий раз откроете вспомогательную таблицу данных, столбцы, в которых показаны избыточные данные, будут скрыты снова. [54]
Отметим, что выбор ИМД осуществляет администратор БД па основе операционных характеристик. Введение двух ИМД, связанных между собой, позволяет решать вопросы включения и удаления данных. Основные недостатки: отношение многие ко многим реализуется очень сложно, дает громоздкую структуру и требует хранения избыточных данных, что особенно нежелательно на физическом уровне; иерархическая упорядоченность усложняет операции удаления и включения; доступ к любой вершине возможен только через корневую, что увеличивает время доступа. [55]
Экспериментальное определение динамических характеристик систем с постоянными параметрами ( линейных и нелинейных) в некотором смысле является задачей несложной, по крайней мере по сравнению с определением характеристик систем с переменными параметрами. При разработке приспосабливающихся систем автоматического управления нельзя рассчитывать на то, что для выполнения измерений имеется много времени. Эксперименты должны проводиться за время, обычно малое по сравнению со временем изменения параметров системы, иначе полученные данные не будут иметь никакого смысла. Нельзя полагаться и на то, что можно будет проверять правильность полученных результатов и учесть ошибки измерения, ибо избыточные данные необходимо запоминать, что во многих системах нелегко осуществить. [56]
Иногда большое число пар вход-выход, относящихся к одному и тому же участку рабочего диапазона системы, доминируют в экспериментальном множестве. При обучении нейронной сети это приводит к отображению данных именно из этого диапазона. Помимо более длительного обучения нейронной сети, это является причиной неадекватности модели, т.е. конечная модель хорошо представляет систему только в некоторой области рабочего диапазона, становясь неадекватной в других областях. Удаление избыточных данных уменьшает размер обучающего множества, делая его одновременно более репрезентативным, что положительно сказывается на качестве модели и скорости обучения. [57]
Страницы: 1 2 3 4