Длина - кодовое ограничение
Cтраница 1
Длина кодового ограничения сверточногоукода, определяемая как yv vL, равна числу символов канала, выходящих из декодера в течение времени между поступлением данного символа источника в кодер и выходом его из кодера. Длина кодового ограничения сверточ-ного кода играет ту же роль, что и длина блока в блоковом коде. [1]
 |
Логический блок, предназначенный - для осуществления операции сложения, сравнения и выбора. [2] |
Требования к памяти декодера, работающего согласно алгоритму Витерби, растут с увеличением длины кодового ограничения как степенная функция. Для кода со степенью кодирования 1п после каждого шага декодирования декодер держит в памяти набор из 2 путей. [3]
Месси [1963] 1 оказал, что вероятность ошибки для лучших пороговых декодеров независимо от длины кодового ограничения отлична от нуля. [4]
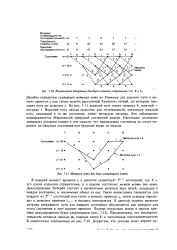 |
Решетчатая диаграмма декодера ( степень кодирования 1 / 2. [5] |
В каждый момент времени г, в решетке существует 2 - состояний, где К - это длина кодового ограничения, и в каждое состояние может войти два пути. Декодирование Витерби состоит в вычислении метрики двух путей, входящих в каждое состояние, и исключении одного из них. Такие вычисления проводятся для каждого из 2 - состояний или узлов в момент времени /; затем декодер переходит к моменту времени tl l, и процесс повторяется. В данный момент времени метрика выжившего пути для каждого состояния обозначается как метрика для этого состояния в этот момент времени. [6]
Главный недостаток декодирования по алгоритму Витерби заключается в том, что в то время, как вероятность появления ошибки экспоненциально убывает с ростом длины кодового ограничения, число кодовых состояний, а значит сложность декодера, экспоненциально растет с увеличением длины кодового ограничения. Последовательное декодирование асимптотически достигает той же вероятности появления ошибки, что и декодирование по принципу максимального правдоподобия, но без поиска всех возможных состояний. Фактически при последовательном декодировании число перебираемых состояний существенно независимо от длины кодового ограничения, и это позволяет использовать очень большие ( К 41) длины кодового ограничения. Это является важным фактором при обеспечении таких низких вероятностей появления ошибок. Основным недостатком последовательного декодирования является то, что количество перебираемых метрик состояний является случайной величиной. При низком SNR приходится перебирать больше гипотез, чем при высоком SNR. Из-за такой изменчивости вычислительной нагрузки, поступившие последовательности необходимо сохранять в буфере памяти. [7]
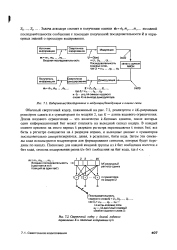 |
Кодирование / декодирование и модуляция / демодуляция в канале связи.| Сверточный кодер с длиной кодового ограничения К и степенью кодирования k / n. [8] |
Обычный сверточный кодер, показанный на рис. 7.2, реализуется с М - разрядным регистром сдвига и п сумматорами по модулю 2, где К - длина кодового ограничения. Длина кодового ограничения - это количество / t - битовых сдвигов, после которых один информационный бит может повлиять на выходной сигнал кодера. В каждый момент времени на место первых k разрядов регистра перемещаются k новых бит; все биты в регистре смещаются на k разрядов вправо, и выходные данные п сумматоров последовательно дискретизируются, давая, в результате, биты кода. Затем эти символы кода используются модулятором для формирования сигналов, которые будут переданы по каналу. [9]
Схему ТСМ можно реализовать с помощью сверточного кодера, где k текущих битов и К-1 предыдущих битов используются для получения nk p кодовых битов, где К - длина кодового ограничения кодера ( см. главу 7), а р - число битов четности. Этого можно достичь путем кодирования со степенью ld ( k 1) с последующим отображением групп из ( k 1) бит в набор из 2 1 сигналов. Аналогично на рис. 9.21, б показан набор сигналов с 4-ричной модуляцией PSK ( QPSK) до и после перекодирования кодом со степенью кодирования 2 / 3 в 8-ричные сигналы PSK. Подобным образом на рис. 9.21, в показаны некодированные 16-ричные сигналы QAM до и после перекодирования кодом со степенью кодирования 4 / 5 в 32-ричные сигналы QAM. В каждом из случаев, показанных на рис. 9.21, система сконфигурирована таким образом, чтобы до и после кодирования средняя мощность сигнала была одинаковой. Таким образом, М 2Л /; однако увеличение размера алфавита не приводит к увеличению требуемой ширины полосы частот. Напомним из раздела 9 7.2, что ширина полосы пропускания при неортогональной передаче сигнала не зависит от плотности точек сигналов в множестве; она зависит только от скорости передачи сигнала. [10]
 |
Диаграмма состояний с обозначенными расстояниями до нулевого пути. [11] |
Для оценки пространственных характеристик при большой длине кодового ограничения передаточную функцию T ( D) использовать нельзя, поскольку сложность T ( D) экспоненциально растет с увеличением длины кодового ограничения. [12]
В этой главе мы описали значительную структурную разницу между блочными и сверточными кодами - сверточные коды со степенью кодирования 1 / я сохраняют в памяти предыдущие К - 1 бит, где К означает длину кодового ограничения. С такой памятью кодирование каждого входного бита данных зависит не только от значения этого бита, н о и от предшествующих ему К - 1 бит. [13]
Главный недостаток декодирования по алгоритму Витерби заключается в том, что в то время, как вероятность появления ошибки экспоненциально убывает с ростом длины кодового ограничения, число кодовых состояний, а значит сложность декодера, экспоненциально растет с увеличением длины кодового ограничения. Последовательное декодирование асимптотически достигает той же вероятности появления ошибки, что и декодирование по принципу максимального правдоподобия, но без поиска всех возможных состояний. Фактически при последовательном декодировании число перебираемых состояний существенно независимо от длины кодового ограничения, и это позволяет использовать очень большие ( К 41) длины кодового ограничения. Это является важным фактором при обеспечении таких низких вероятностей появления ошибок. Основным недостатком последовательного декодирования является то, что количество перебираемых метрик состояний является случайной величиной. При низком SNR приходится перебирать больше гипотез, чем при высоком SNR. Из-за такой изменчивости вычислительной нагрузки, поступившие последовательности необходимо сохранять в буфере памяти. [14]
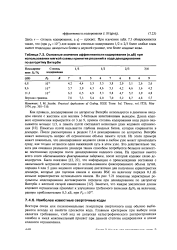 |
Основные значения эффективности кодирования ( в дБ при использовании мягкой схемы принятия решений в ходе декодирования по алгоритму Витерби. [15] |
Страницы: 1 2 3