Длина - кодовое ограничение
Cтраница 2
Как правило, декодирование по алгоритму Витерби используется в двоичном входном канале с жестким или мягким 3-битовым квантованным выходом. Длина кодового ограничения варьируется от 3 до 9, причем степень кодирования кода редко оказывается меньше 1 / 3, и память путей составляет несколько длин кодового ограничения [12], Памятью путей называется глубина входных битов, которая сохраняется в декодере. После рассмотрения в разделе 7.3.4 декодирования по алгоритму Витерби может возникнуть вопрос об ограничении объема памяти путей. Из этого примера может показаться, что декодирование кодового слова в любом узле может происходить сразу, как только останется один выживший путь в этом узле. Это действительно так; хотя для создания реального декодера таким способом потребуется большое количество постоянных проверок после декодирования кодового слова. На практике вместо всего этого обеспечивается фиксированная задержка, после которой кодовое слово декодируется. Было показано [12, 22], что информации о происхождении состояния с наименьшей метрикой состояния ( с использованием фиксированного объема путей, порядка 4 или 5 длин кодового ограничения) достаточно для получения характеристик декодера, которые для гауссова канала и канала BSC на величину порядка 0 1 дБ меньше характеристик оптимального канала. [16]
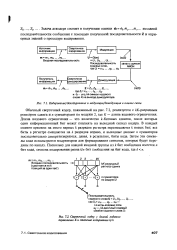 |
Кодирование / декодирование и модуляция / демодуляция в канале связи.| Сверточный кодер с длиной кодового ограничения К и степенью кодирования k / n. [17] |
Обычный сверточный кодер, показанный на рис. 7.2, реализуется с М - разрядным регистром сдвига и п сумматорами по модулю 2, где К - длина кодового ограничения. Длина кодового ограничения - это количество / t - битовых сдвигов, после которых один информационный бит может повлиять на выходной сигнал кодера. В каждый момент времени на место первых k разрядов регистра перемещаются k новых бит; все биты в регистре смещаются на k разрядов вправо, и выходные данные п сумматоров последовательно дискретизируются, давая, в результате, биты кода. Затем эти символы кода используются модулятором для формирования сигналов, которые будут переданы по каналу. [18]
Длина кодового ограничения сверточногоукода, определяемая как yv vL, равна числу символов канала, выходящих из декодера в течение времени между поступлением данного символа источника в кодер и выходом его из кодера. Длина кодового ограничения сверточ-ного кода играет ту же роль, что и длина блока в блоковом коде. [19]
Рассмотрим сверточный кодер со степенью кодирования 2 / 3, показанный на рис. 37.6. За раз в кодер подается k 2 бит; п 3 бит подается на выход кодера. Имеется kK 4 разряда регистра, и длина кодового ограничения равна К - 2 в единицах 2-битовых байтов. [20]
Для кодера с k l, за - и момент времени бит сообщения т, будет перемещен на место первого разряда регистра сдвига; все предыдущие биты в регистре будут смещены на один разряд вправо, а выходной сигнал п сумматоров будет последовательно оцифрован и передан. Отметим, что для кодера со степенью кодирования 1 /, kK - разрядный регистр сдвига для простоты можно называть АГ-разрядным регистром, а длину кодового ограничения К, которая выражается в единицах разрядов - кортежей, можно именовать длиной кодового ограничения в битах. [21]
Векторы связи или полиномиальные генераторы сверточного кода обычно выбираются исходя из свойств просветов кода. Главным критерием при выборе кода является требование, чтоб код не допускал катастрофического распространения ошибок и имел максимальный просвет при данной степени кодирования и длине кодового ограничения. [22]
Как правило, декодирование по алгоритму Витерби используется в двоичном входном канале с жестким или мягким 3-битовым квантованным выходом. Длина кодового ограничения варьируется от 3 до 9, причем степень кодирования кода редко оказывается меньше 1 / 3, и память путей составляет несколько длин кодового ограничения [12], Памятью путей называется глубина входных битов, которая сохраняется в декодере. После рассмотрения в разделе 7.3.4 декодирования по алгоритму Витерби может возникнуть вопрос об ограничении объема памяти путей. Из этого примера может показаться, что декодирование кодового слова в любом узле может происходить сразу, как только останется один выживший путь в этом узле. Это действительно так; хотя для создания реального декодера таким способом потребуется большое количество постоянных проверок после декодирования кодового слова. На практике вместо всего этого обеспечивается фиксированная задержка, после которой кодовое слово декодируется. Было показано [12, 22], что информации о происхождении состояния с наименьшей метрикой состояния ( с использованием фиксированного объема путей, порядка 4 или 5 длин кодового ограничения) достаточно для получения характеристик декодера, которые для гауссова канала и канала BSC на величину порядка 0 1 дБ меньше характеристик оптимального канала. [23]
Для кодера с k l, за - и момент времени бит сообщения т, будет перемещен на место первого разряда регистра сдвига; все предыдущие биты в регистре будут смещены на один разряд вправо, а выходной сигнал п сумматоров будет последовательно оцифрован и передан. Отметим, что для кодера со степенью кодирования 1 /, kK - разрядный регистр сдвига для простоты можно называть АГ-разрядным регистром, а длину кодового ограничения К, которая выражается в единицах разрядов - кортежей, можно именовать длиной кодового ограничения в битах. [24]
Главный недостаток декодирования по алгоритму Витерби заключается в том, что в то время, как вероятность появления ошибки экспоненциально убывает с ростом длины кодового ограничения, число кодовых состояний, а значит сложность декодера, экспоненциально растет с увеличением длины кодового ограничения. Последовательное декодирование асимптотически достигает той же вероятности появления ошибки, что и декодирование по принципу максимального правдоподобия, но без поиска всех возможных состояний. Фактически при последовательном декодировании число перебираемых состояний существенно независимо от длины кодового ограничения, и это позволяет использовать очень большие ( К 41) длины кодового ограничения. Это является важным фактором при обеспечении таких низких вероятностей появления ошибок. Основным недостатком последовательного декодирования является то, что количество перебираемых метрик состояний является случайной величиной. При низком SNR приходится перебирать больше гипотез, чем при высоком SNR. Из-за такой изменчивости вычислительной нагрузки, поступившие последовательности необходимо сохранять в буфере памяти. [25]
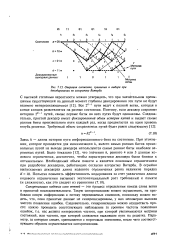 |
Операция сложения, сравнения и выбора при декодировании по алгоритму Витерби. [26] |
При уточнении, которое проводится для минимизации h, вместо самых ранних битов произвольных путей на выходе декодера используются самые ранние биты наиболее вероятных путей. Было показано [12], что значения h, равного 4 или 5 длинам кодового ограничения, достаточно, чтобы характеристики декодера были близки к оптимальным. Необходимый объем памяти и является основным ограничением при разработке декодеров, работающих согласно алгоритму Витерби. [27]
Как правило, параметры устройства чередования, используемого совместно с кодом с коррекцией одиночных ошибок, выбираются таким образом, чтобы число столбцов N превышало ожидаемую длину пакета. Выбираемое число строк зависит от того, какая схема кодирования будет использована. Для блочных кодов М должно быть больше длины кодового блока; для сверточных кодов М должно превышать длину кодового ограничения. Поэтому пакет длиной N может вызвать в блоке кода ( самое большее) одиночную ошибку; аналогично в случае сверточных кодов в пределах одной длины кодового ограничения будет не более одной ошибки. [28]
Главный недостаток декодирования по алгоритму Витерби заключается в том, что в то время, как вероятность появления ошибки экспоненциально убывает с ростом длины кодового ограничения, число кодовых состояний, а значит сложность декодера, экспоненциально растет с увеличением длины кодового ограничения. Последовательное декодирование асимптотически достигает той же вероятности появления ошибки, что и декодирование по принципу максимального правдоподобия, но без поиска всех возможных состояний. Фактически при последовательном декодировании число перебираемых состояний существенно независимо от длины кодового ограничения, и это позволяет использовать очень большие ( К 41) длины кодового ограничения. Это является важным фактором при обеспечении таких низких вероятностей появления ошибок. Основным недостатком последовательного декодирования является то, что количество перебираемых метрик состояний является случайной величиной. При низком SNR приходится перебирать больше гипотез, чем при высоком SNR. Из-за такой изменчивости вычислительной нагрузки, поступившие последовательности необходимо сохранять в буфере памяти. [29]
 |
Кодер сверточного кода. [30] |
Страницы: 1 2 3